
本文主要是针对序列型任务(即输出为一个序列的任务,例如图片描述、机器翻译、序列标注等)提出了一种基于对抗的主动学习算法框架。
主动学习(active learning)介绍
主动学习(active learning)是一种解决监督学习中标记数据不足这一问题的方法。
在实际的监督学习任务中,往往会面临的情况就是:能够获取到大量的未标注数据,但是限于人力、物力,能做标注的数据量则十分有限(对于序列型任务更加棘手,因为序列型任务的标注往往还需要专业领域的知识,无法通过众包给大众的方式进行标注)。比如能够获取到10000条未标注数据,但可能只能标注其中的10%,1000条,这时如何选择这1000条就显得尤为关键,因为不同的标注数据带给模型的提升是不同的。原文中举了一个图片分类的例子:假设现在标注的数据池中包含了sports类别的各种图片(例如足球、篮球、羽毛球等),模型已经基于这些标注数据进行了训练。现在给定了两张未标注的图片,一张是关于swimming,另一张是关于a plate of food,作者认为选择后者进行标注、学习能够带给模型的提升更大,因为它相比前者为模型引入了更多的知识。
所以主动学习想要解决的问题就是:在庞大的未标注的数据集中,如何选取有限量的数据进行标注(称为query sample selection),使得模型能够获得最优的性能。由于这些待标注的数据相当于是由模型“主动”选择出来,提出进行标注的,所以就被称为“主动学习”。
传统的主动学习算法
传统的主动学习方法一般都基于目前的分类器(模型),为unlabeled集合中的每一条unlabeled sample进行预测,然后对模型此次预测的不确定性作一个评价。得分最高(模型最不确定)的若干个sample就作为下一步需要标注的样本。
从分类器中导出的不确定性评价有如下几种:
-
根据预测的置信度(confidence score)进行的评价
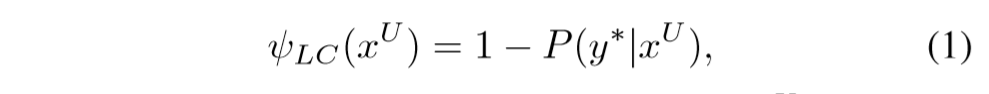
表示需要选出模型预测的置信度最低的若干条未标注样本进行标注。
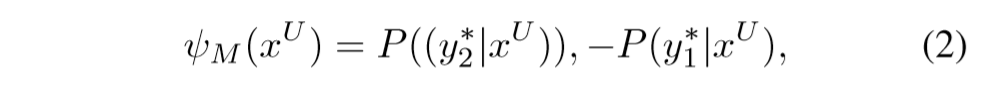
公式(2)则采用了margin的形式,对于每一条未标注样本,选出最优和次优的两个预测序列,选择两者置信度的差值最相近(表示模型不确定是y1*还是y2*)的未标注样本进行标注。 -
根据模型的熵(sequence entropy)进行的评价
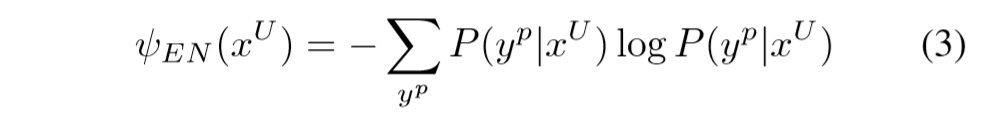
公式(3)枚举所有可行的序列(类别),使用模型对每个序列的评分算出一个熵值,作为不确定性的评价指标。
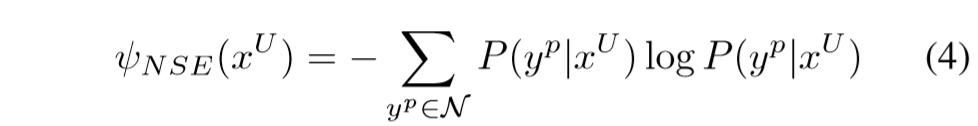
公式(4)相比公式(3)则使用了分值最高的N个序列去计算熵值,而不是所有可行序列。
序列型任务相比于分类任务的难点
- 冷启动问题:当开始标注的序列样本较少时,模型对于序列的预测可能很不准,那么基于这种不准的模型去导出预测的不确定性,从而去未标注的数据集中选择下一步要标注的样本,这个过程本身也会不准。
- 预测序列的空间过于庞大,对于长度为
k的预测序列,每个token可能有p种,那么总共的序列就有p^k种,基于上面说的传统的不确定性评价方法,其复杂度会基于序列长度k呈指数级别上升。因此很将传统的应用于分类任务的主动学习方法引入到序列任务中。
本文提出的模型
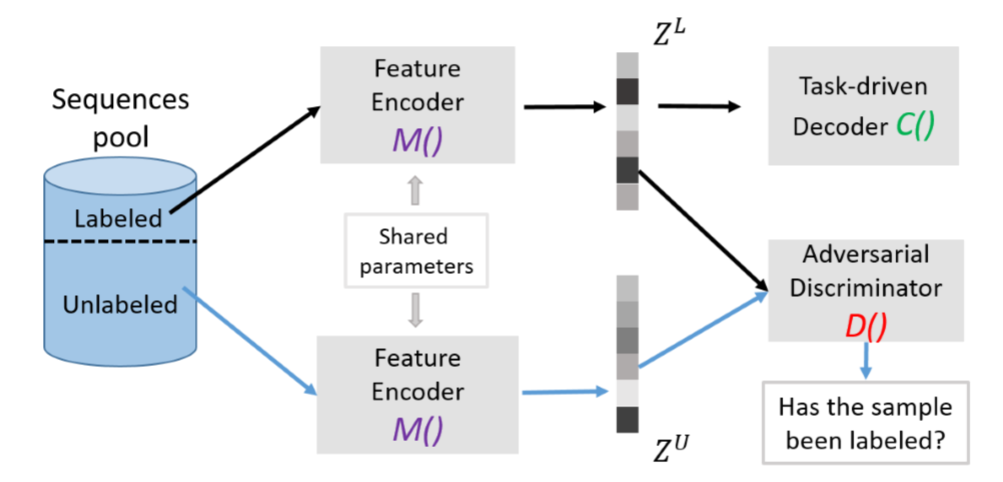
本文提出了一个基于对抗的主动学习算法框架,结合encoder-decoder框架,去处理主动学习过程中的query sample selection的问题。
模型的结构如上图所示,根据不同的功能相当于可以分成两条线:
其一是针对于序列任务的encoder-decoder框架,encoder(图中的M())负责对样本进行特征提取和编码,将其转换成一个中间向量Z,随后这个中间向量交由decoder(图中的C())进行解码,形成预测的序列。这里的encoder和decoder可以整体视为一个黑箱,论文并不关心encoder/decoder具体采用怎样的模型。
其二是为了解决主动学习中的query sample selection问题(也就是从未标注的样例集合中怎样选取下一步要标注的样例)。本文的模型是基于对抗的,就是图中特征编码器M()和分类器D()的对抗。分类器D()相当于需要做一个二分类任务,目标是判别出某个具体的样本采样自labeled pool还是unlabeled pool。而特征编码器M()除了要学习出样本的特征,获得更好的样本编码供decoder使用以外,还需要使得encoder能够迷惑分类器D(),使之无法判别出该样本采样自labeled pool还是unlabeled pool。
训练时采用的损失函数如下:
M()的损失函数为:
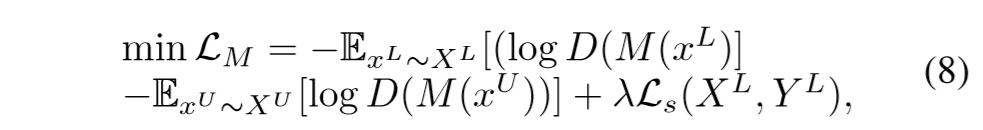
其中的前两项表示和判别器D()对抗的损失(可理解为迷惑判别器D()所获得的奖励),而最后一项针对已标注的数据,预测序列与真实序列之间的损失,具体为:
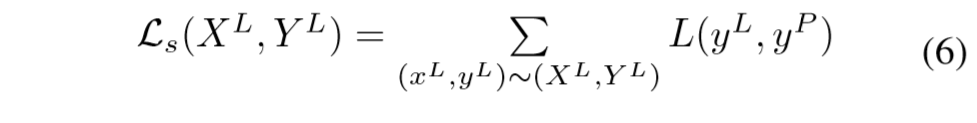
其中的L(·)可以是任意的评价两个序列相似程度的损失函数D()的损失函数为:
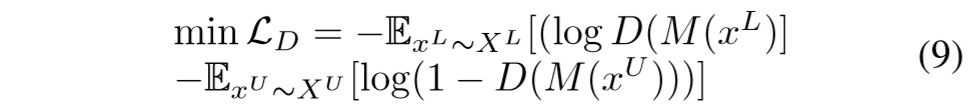
即正确区分出样本labeled or unlabeled所获得的奖励。
对抗的训练过程如下图所示:
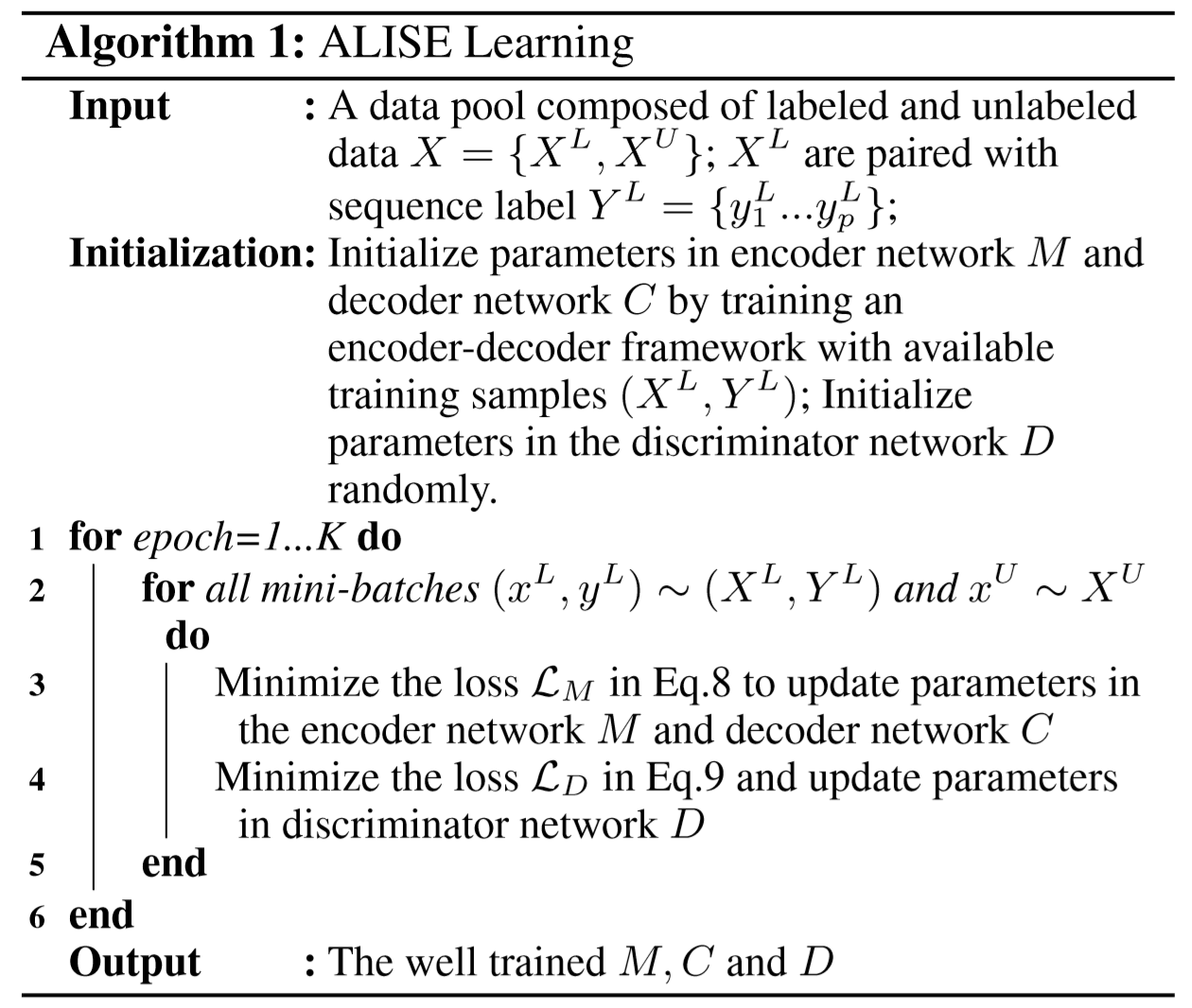
当每一次的模型训练完毕后,一方面M()和C()能够相互配合,生成和真实序列相近的预测序列;另一方面,可以使用判别器D()去评价:未标注的样本集中的样本与当前模型的匹配程度。如果D(M(x_unlabeled))得分较高,则说明D()认为这条样本大概率来自labeled pool,也就可以认为这条样本与现有已标注样本集的覆盖程度较高;相反,如果D(M(x_unlabeled))得分较低,说明这条样本和已标注样本集的覆盖程度较低,其包含当前模型没有学到的知识的程度较大,因此适合选出来进行标注。
实验
本文提出的模型分别在两个序列任务:slot-filling和image-captioning上进行了实验,这里只介绍对第一个任务(slot-filling)的实验。
数据集
采用的是ATIS(预定机票)的数据集。
采用模型
- 编码器:采用了双向LSTM,64个隐层结点。word-embedding维度为128。最后得到的中间表示向量的维度为128(2 * 64)维。
- 解码器:本文分别尝试了两种解码器:1. 标准的LSTM解码器;2. 加了attention机制的LSTM解码器。
- 判别器
D():三层全连接:128 - 64 - 1,输入和中间层使用relu作为激活函数,输出层会过一个sigmoid函数,得到0-1之间的得分,表示属于labeled pool的概率。
结果
训练时每次选取数据中的10%进行训练(视为由主动学习框架选出的下一步要标注的数据),最后得出模型效果随标注数据百分比的变化情况如下:
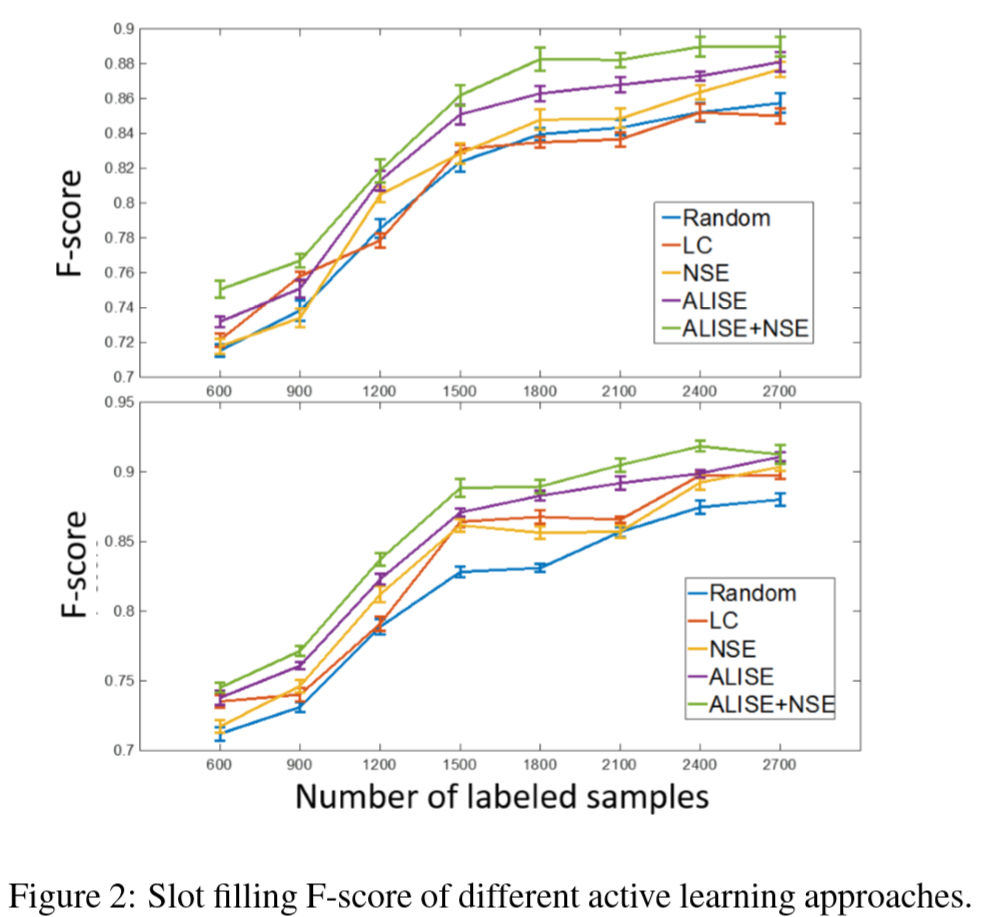
其中两张图分别对应上面提到的使用的两个解码器(上图为标准LSTM,下图为加了attention机制)。
每张图中的不同颜色的折线表示对不同的主动学习方法之间的比较:Random表示随机从未标注数据集中选取10%的数据进行标注;LC/NSE分别为上文提到过对于query sample selection的几种传统的不确定性评价方法;ALISE则是本文提出的这个方法;而ALISE+NSE表示本文提出的方法和NSE方法的综合评价。
可以看到,在标注的数据量占全部数据百分比一定时,ALISE方法所获得的模型效果基本上领先于其他的主动学习评价方法。而综合ALISE和NSE的评价方法则更为优秀。