
这篇文章将基于以下三篇论文,对NLP领域中应用对抗式方法解决相关问题的模型、算法做一个综述:
- Chen et al. 2017. Adversarial Multi-Criteria Learning for Chinese Word Segmentation
- Fu et al. 2018. Style Transfer in Text: Exploration and Evaluation. AAAI-18
- Deng et al. 2018. Adversarial Active Learning for Sequence Labeling and Generation. IJCAI-18
论文1:对抗式方法解决多标准下的中文分词问题
本文拟解决的问题
在中文分词领域中,常常存在许多不同的分词标准(criteria),如下图所示:
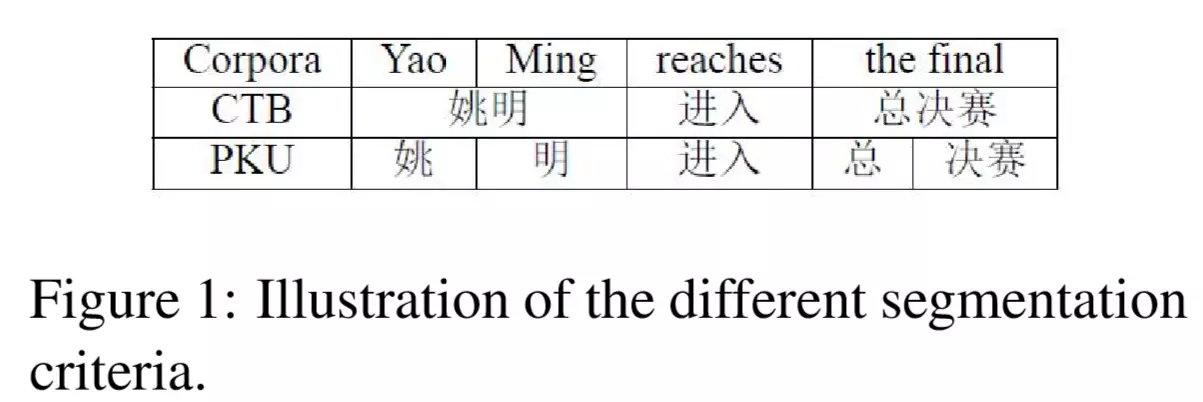
可以看到在上面两个语料集中,使用了不同的标准对同一句话“姚明进入总决赛”进行分词,得到了不同的结果。
此前的大部分方法都是针对单一分词标准进行的分词模型研究,本文提出的模型旨在将不同标准的语料库一起利用起来,进行多任务联合训练,通过对公共特征的学习,帮助提升各个子任务的分词性能。
本文提出的模型
本文提出的多任务(多分词标准)联合训练模型如下图所示:
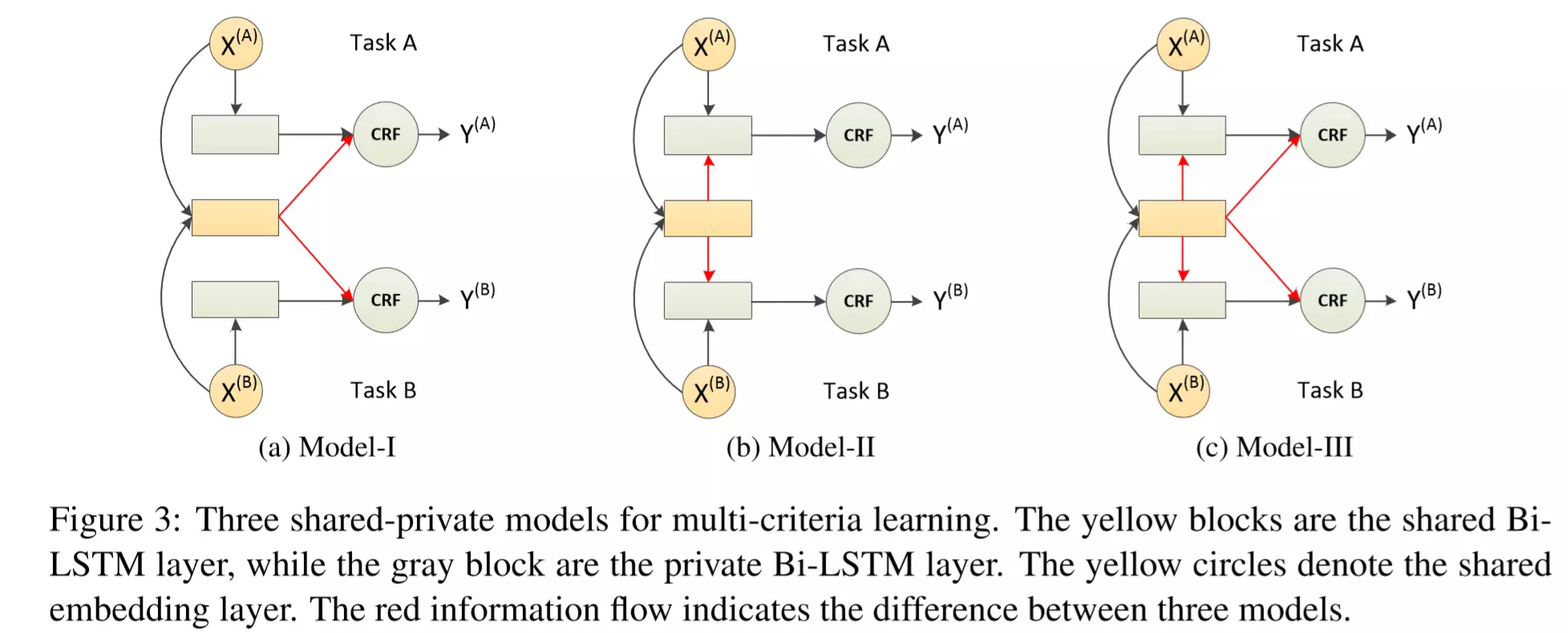
其中:黄色的方框是共享的Bi-LSTM层,灰色的方框是每个任务私有的Bi-LSTM层。黄色的圆圈是多任务共享的word-embedding层。
这三个模型(Model-I ~ Model-III)的差别就是共享Bi-LSTM层数据的流向不同,如图中的红色箭头所示。虽然图中只放了两个Task,但实际上可以有多个Task,它们分别有各自的Bi-LSTM层和CRF层,并且使用共享Bi-LSTM层提供的信息。
多任务联合训练模型(需要最大化)的目标函数如下:
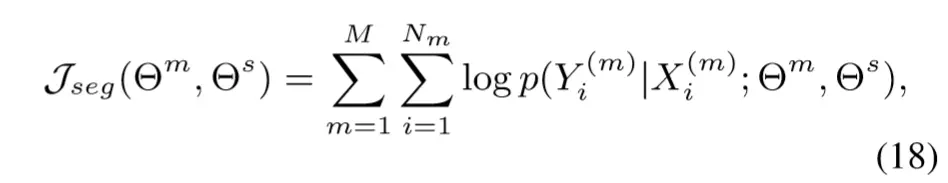
这个目标函数是面向任务的,论文中将其称为task loss。
在上述多任务联合训练模型的基础上,作者受到一些对抗式模型(共三篇,见引文)的启发,加入了对抗判别器如下:
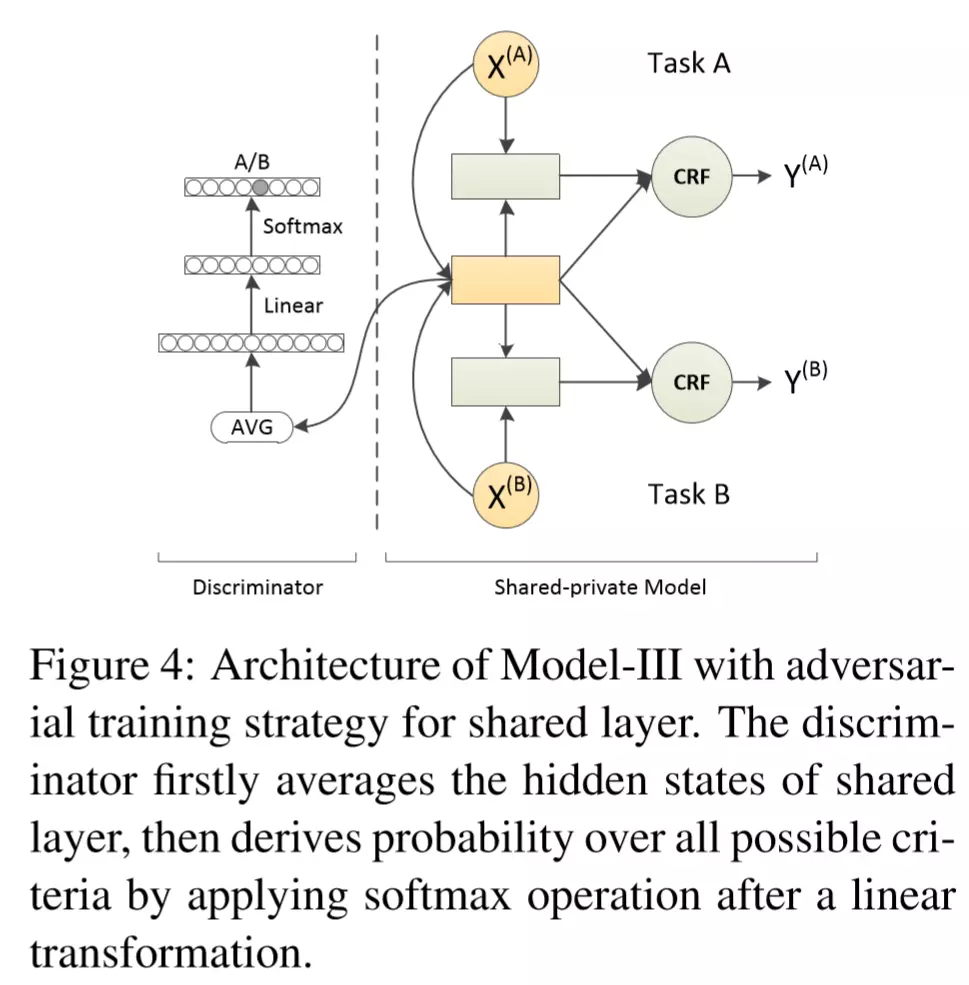
其结构为:将输入句子通过共享Bi-LSTM层,将每个时间步的hidden state取平均,然后过一个线性映射,再过一个softmax,最后向量中的每个值就表示对应的各个任务的分数。
对抗判别器的目标是:正确区分出给定sentence属于哪一个任务。因此其目标函数如下:
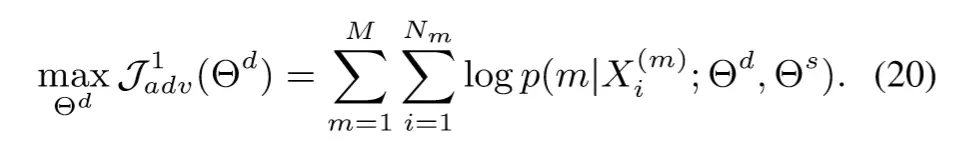
而shared Bi-LSTM的目标是和判别器对抗的,即:不让判别器区分出给定sentence属于哪一个任务,因此其目标函数如下:
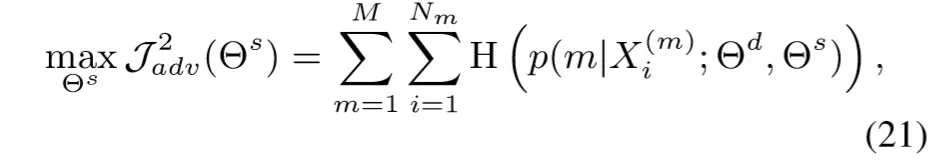
以上两者是判别器和shared Bi-LSTM相互对抗的loss,作者称其为adversarial loss。
最终任务的损失函数如下:
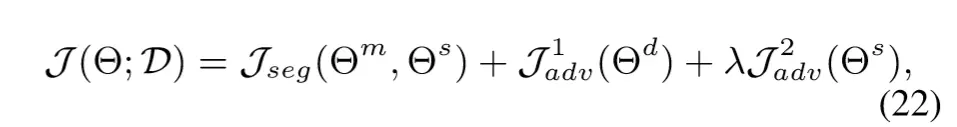
训练过程是交替进行的,如下:

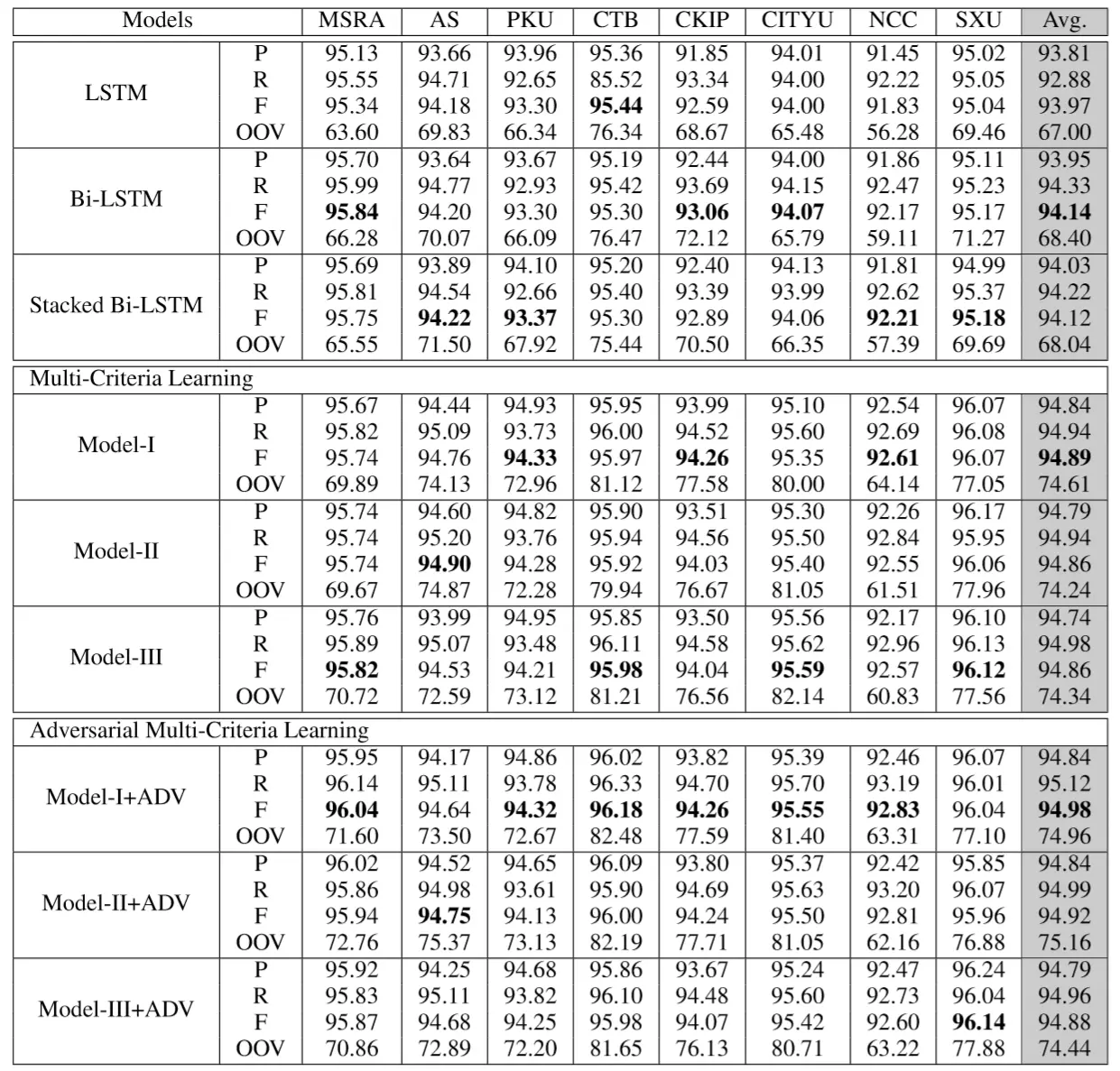
实验结果
相关引文
论文中引用的三篇做对抗式的论文:
- Ajakan et al. 2014. Domain-Adversarial Neural Networks.
- Ganin et al. 2016. Domain-Adversarial Training of Neural Networks.
- Bousmalis et al. 2016. Domain Separation Networks.
论文2:对抗式方法解决文本风格迁移问题
本文拟解决的问题
图像领域的风格迁移已经取得进展,但文本领域的风格迁移相比图像领域进展缓慢,作者认为有以下两个原因:
- 缺少平行数据(相同语义、不同表述风格的数据集)
- 缺少可靠的评价方法
本文就尝试解决文本领域风格迁移的上述两个问题,从而推动文本领域风格迁移的发展。
本文的贡献
本文的贡献在以下三个方面:
- 提出了一个论文风格-新闻风格的标题数据集以促进文本领域风格迁移的研究
- 提出了文本风格迁移两个评价方法:风格转换能力、内容保留度,并且作者认为这两个评价指标和人类的标准高度吻合
- 提出了文本风格迁移的两个模型,并在上述评价方法上进行验证,发现两个模型在不同情形下各有所长
相关工作、引文
图像领域的风格迁移
- 分离图像的内容和风格信息,然后将它们重新融合以生成新图片:Gatys, L. A.; Ecker, A. S.; and Bethge, M. 2016. Image style transfer using convolutional neural networks. In Pro-ceedings of the IEEE Conference on Computer Vision andPattern Recognition, 2414–2423.
- 使用一个简单的线性模型来改变图片的颜色(or色调?):Gatys, L. A.; Bethge, M.; Hertzmann, A.; and Shechtman, E. 2016. Preserving color in neural artistic style transfer. arXiv preprint arXiv:1606.05897.
- CycleGAN(有点像自编解码网络):Zhu, J.-Y.; Park, T.; Isola, P.; and Efros, A. A. 2017. Un-paired image-to-image translation using cycle-consistent adversarial networks. arXiv preprint arXiv:1703.10593.
- 将图像风格迁移视作领域迁移:Li, Y.; Wang, N.; Liu, J.; and Hou, X. 2017. Demystifying neural style transfer. InIJCAI.
文本领域的风格迁移
- 用到了Pointer Networks将现代英语翻译成莎士比亚英语:
- 还提到了一些别的论文,但我感觉没必要看(也看不懂),涉及到两篇使用VAE做生成的。
Adversarial Networks for Domain Separation
这其实就是这篇综述中,三篇论文类似的思路,只是适用范围变广了(多分词标准、风格转换、迁移学习、多任务学习等等),实际上本质上还是相同的(目的都是为了学习到公共的、与具体xxx无关的知识)。其实最早在2015年就有人用这样的思路做Domain Separation了。
总结
这篇文章的引文部分内容还挺多的,可以之后有时间了看一看,顺便多了解一些生成领域的知识。其中提到的一些比较有意思的模型有:
- Pointer Networks, 主要用于解决seq2seq问题中,decoder端的输出项依赖encoder的输入项的问题
- CycleGAN,具体还没有看是用来干啥的
- VAE,貌似涉及理论的东西比较多,很难看懂…
本文提出的模型
本文提出了两种不同的模型,这两种模型的不同只是在于Decoder端,其他的部分(包括对抗判别器)都是相同的。
模型一(图左)对每个style单独训练一个decoder;而模型二(图右)只训练一个共同的decoder,通过lookup的方式获取不同style的style embedding(类似word embedding),并将其传入共同的这一个decoder。
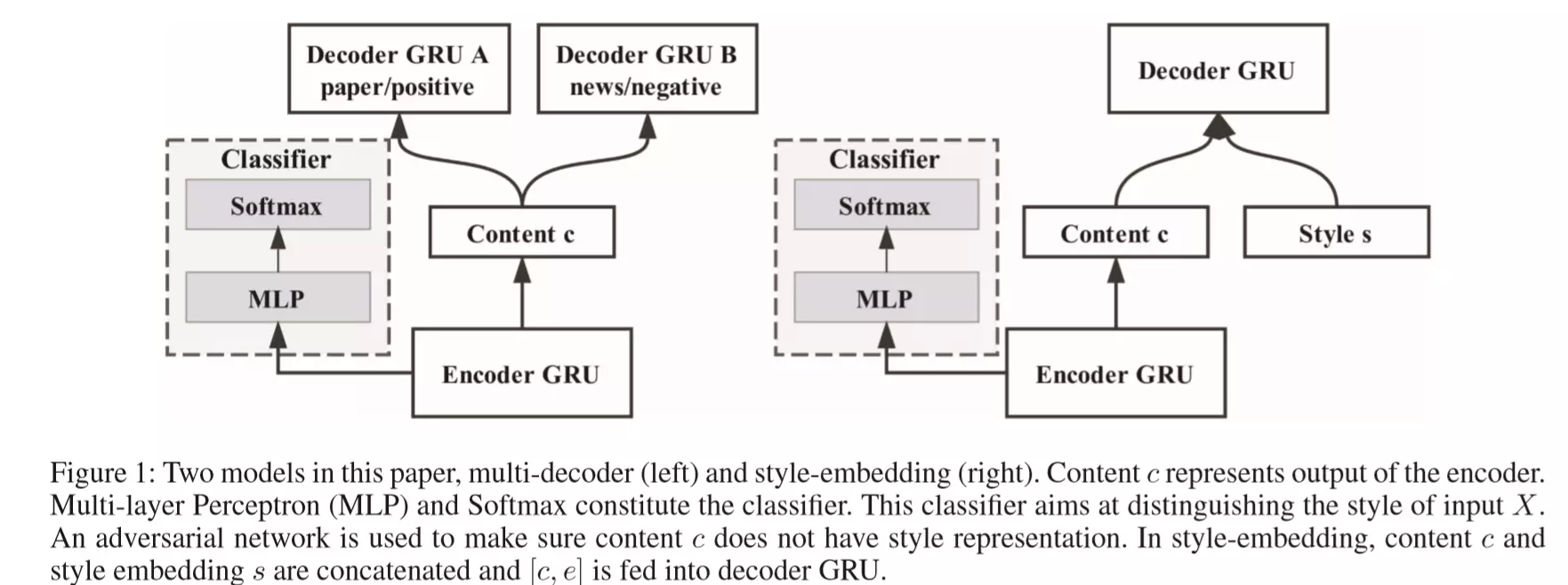
这两个模型都采用了传统的做seq2seq的Encoder-Decoder结构作为主体。模型假设:Encoder只提取出文本的内容表示,而不会提取文本的风格信息;而Decoder基于Encoder提取出来的,本文的内容表示(Content c)去重构原始文本。由于之前保证了Encoder只会提取出文本的内容信息(而没有风格信息),那么Decoder相当于就能学习到不同style文本共有的style信息,在此style信息的基础上,对内容信息进行加工,从而重构出原始句子。
因此论文的task loss是要让Decoder的输出去恢复原始句子:
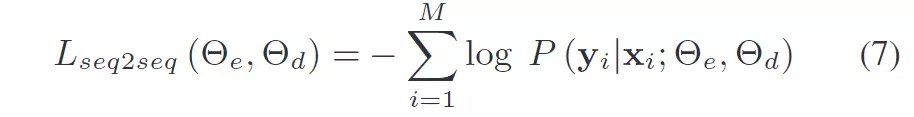
其中和是原始序列和目标序列,它们是相同的(i.e. )。论文称之为seq2seq的自编解码网络(auto-encoder seq2seq model)。
但是光有上面的Encoder-Decoder是无法保证Encoder单单提取出文本的内容信息的。因此这里就采用了对抗式的方法:引入了对抗判别器,接受Encoder编码后的向量,过一个多层感知器和softmax,目标是判别文本的风格(style)。
类似于论文1,这里的loss分成两个部分:task loss和adversarial loss,其中adversarial loss是成对出现的(分别属于对抗的两个主体):
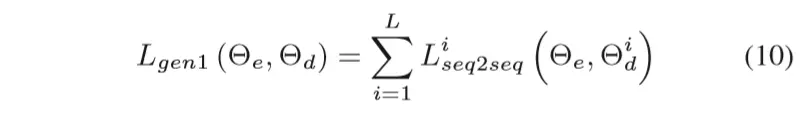
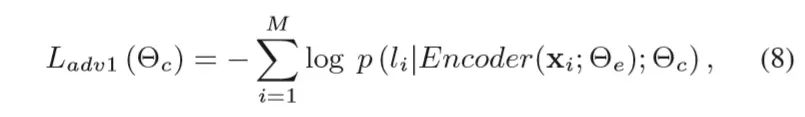
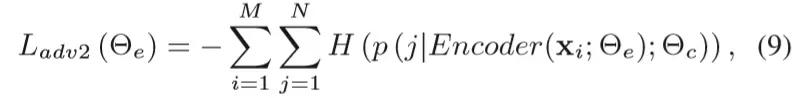
基本和论文1的形式是相同的(只是论文1中是最大化目标函数,这里是最小化loss),因此这里不再展开讲。
最后针对两个模型的总的total loss如下:
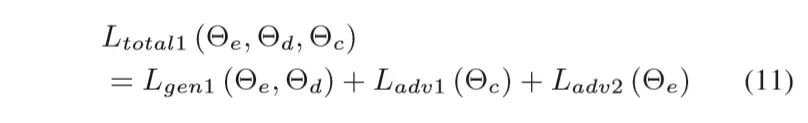
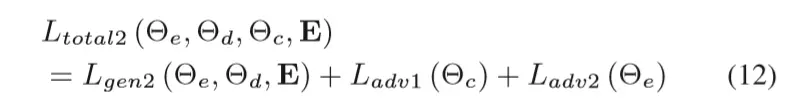
分别属于两个模型。
本文提出的风格迁移的评价方法
Transfer Strength
作者用100,000+数据训练了一个二分类的判别器(可以在这里获取到),去判别文本的风格(news OR paper)。该评价指标的计算方式为:,其中是正确迁移到目标风格的样本数量,而是测试样本总数。
Content Preservation
对于内容保留度,作者采用的是原句和迁移后句子的向量余弦距离。句子的向量被定义为一个三维向量,其每一项分别为对所有的word的embedding做max、mean、min pooling的结果,如下所示:
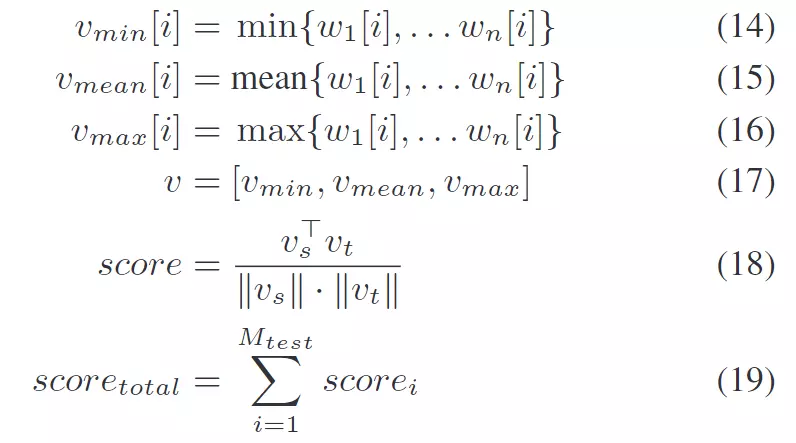
而word embedding采用的是stanford发布的Glove,使用了其中100维的word embedding。
实验结果
数据集
采用了两个数据集,分别是:news-paper title和positive-negative review。两者都是非平行(即没有news2paper一一对应关系)的数据。
实验结果
实验采用了普通的auto-encoder seq2seq model作为对照,在本文提出的两个指标上进行了文本迁移及其评价,结果如下图:
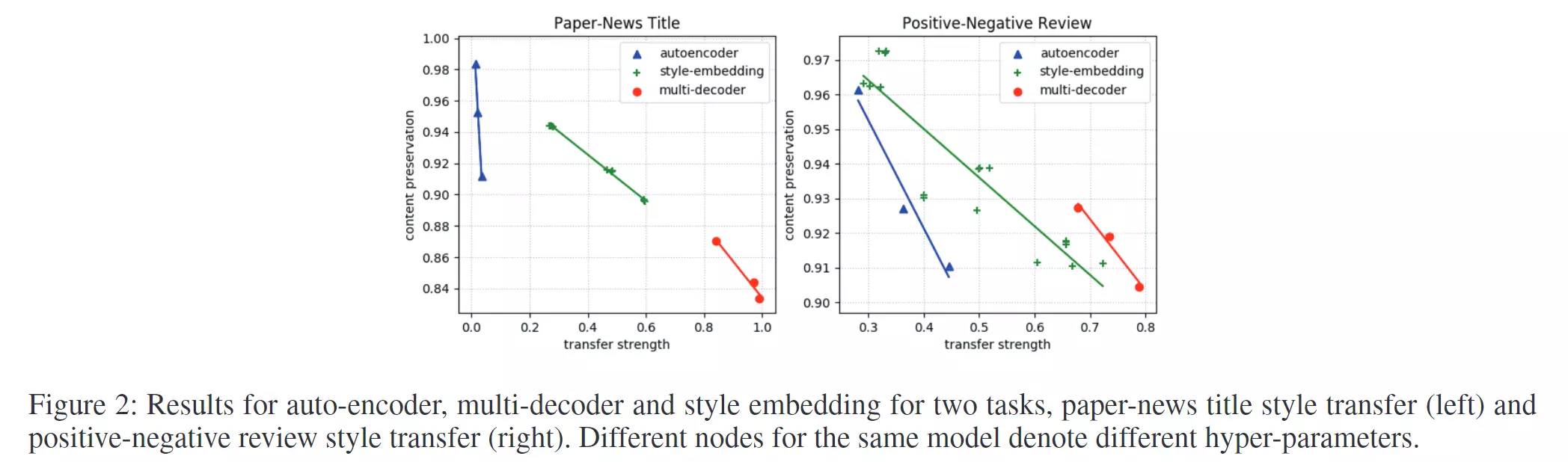
其中不同的结点代表了作者采用的不同的超参数设定。
下图为一些迁移的样本:

可以看到在positive-negative迁移中的效果还是不错的。
论文3:对抗式方法解决针对序列任务的主动学习算法
这篇论文使用对抗要解决的问题就和上两篇论文(多任务、多领域等)有些不太一样。这篇论文使用对抗的目的是解决主动学习中的query sample selection问题,即如何从未标注的数据集中选取下一批要标注的数据。
具体内容详见之前的笔记。这里就不再重复。
总结和思考
Q:这种用对抗的方式做Domain Separation相比非对抗式的训练是否引入了新的信息呢?
A:我觉得是引入了的,就是各个样本取自哪个领域/任务的额外信息。在单纯采用多任务联合训练的模型,而不使用对抗的时候,模型是得不到每个样本取自什么领域/任务这一维度信息的,虽然看上去貌似不同领域/任务的样本被喂入不同的编码器,但模型是不知道它们之间的含义的。而当采用了对抗做Domain Separation后,判别器的损失函数中就包含这一维度的信息了。
其实这种对抗的方法相当于是让多任务联合训练的模型自动去学习了一种动态的损失函数,使得公共编码器尽量只学习公共知识。如果不使用对抗的话,这一点很难做到,因为编码器出来的本身就是无法解释的隐层向量,这个隐层向量中包含了多少的公共知识,包含了多少的领域知识,根本无法直接从这个向量中看出来,所以也就没办法直接对这个向量定义损失函数。而对抗学习了一个判别器,这个判别器能够找各种刁钻的角度去分析这个隐层向量,试图揪出其中一点点的特定领域的信息。所以这个判别器就相当于是对公共编码器定义了一个动态变化的损失函数了。