
AllenNLP是allenai团队开发的,基于Pytorch的进一步封装,从而使得NLP领域的研究者能够更快速、便捷地实现一个模型。本文将对其部分特性、用法等进行介绍。
简介
AllenNLP相当于是为NLP领域研究设计了一堆的可重用组件。
AllenNLP的设计动机:





特性
对NLP领域数据的抽象和封装

NLP任务中的数据往往有一些共性:
- 输入基本都是文本形式,但是神经网络模型需要的是Tensor(数值形式的数据)
- 输入是序列形式的,也就是说有顺序的关联
- 输入的文本序列长短往往不一
基于这些共性,AllenNLP通过一些层次的抽象和封装使得NLP领域的数据处理更加简单。具体来说,AllenNLP认为数据集是样本(instance)的集合,而样本又是多个fields的集合。AllenNLP对这些文本任务中可能出现的fields进行了封装,如下:

在此基础上,AllenNLP还提供了NLP领域数据处理常见的功能,包括:
- 可以用tokenizer进行分词(包括添加首尾token、去除停用词等),当然也可以自己执行tokenize。AllenNLP中提供了两种tokenizer的具体实现:WordTokenizer和CharacterTokenizer
- 通过将每一个field绑定一个token_indexer,从而自动为token创建index、建立词典(Vocabulary),从而能够将数据中的文本转换成对应的one-hot encoding 或 token embedding
- 为文本序列长短不一的问题提供了padding、get_mask等方法
对NLP领域模型的抽象和封装
目前的NLP任务模型往往包含一些广泛使用的结构,例如:
- embedding层
- 编码序列的encoding层,其中又可以分为:
- 多个向量到单个向量(只取最后状态)
- 多个向量到多个向量(每一个时间步的状态)
- attention操作
AllenNLP对上述模型中可能遇到的通用结构进行了抽象,并为每一种都提供了多种具体的实现方法:






这些AllenNLP内置的模型结构均是Pytorch的Module的子类,其文档:https://allenai.github.io/allennlp-docs/api/allennlp.modules.html
对训练过程的封装
allenNLP将训练过程封装成了一个类Trainer,通过参数(可配置)的形式进行重用,从而避免写大量重复代码:

其中可配置项包含:
- 训练的模型
- 优化器Optimizer
- 数据迭代器(对数据集进行batch划分等工作)
- train dataset
- validation dataset(可选)
- 在validation dataset上的评价方式
- early stopping(patience,可选)
- 对梯度的处理(grad_norm, grad_clipping)
- 学习率的变化函数(LearningRateScheduler)
- 自动保存模型的一些配置
- 一些训练过程中记录日志(log)的选项
关于TensorBoard的支持(尚不确定):https://allenai.github.io/allennlp-docs/api/allennlp.training.tensorboard_writer.html
Predictor

PPT中指出了将模型同时用于预测的两个关键点:
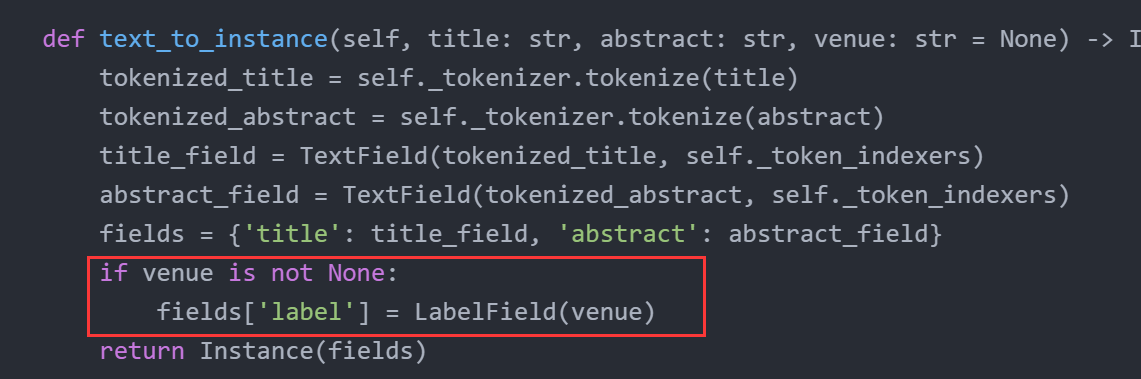
- 使得数据处理对单独的样本(JSON形式)同样适用
- 模型需要在数据不包含label/loss的情况下也能运行
为此AllenNLP抽象了一个类Predictor,用来进行单一样本的预测:

其本质上是一个对单一样本的JSON Wrapper
而对于第二点(模型需要在数据不包含label/loss的情况下也能运行),则通过代码中的判断:
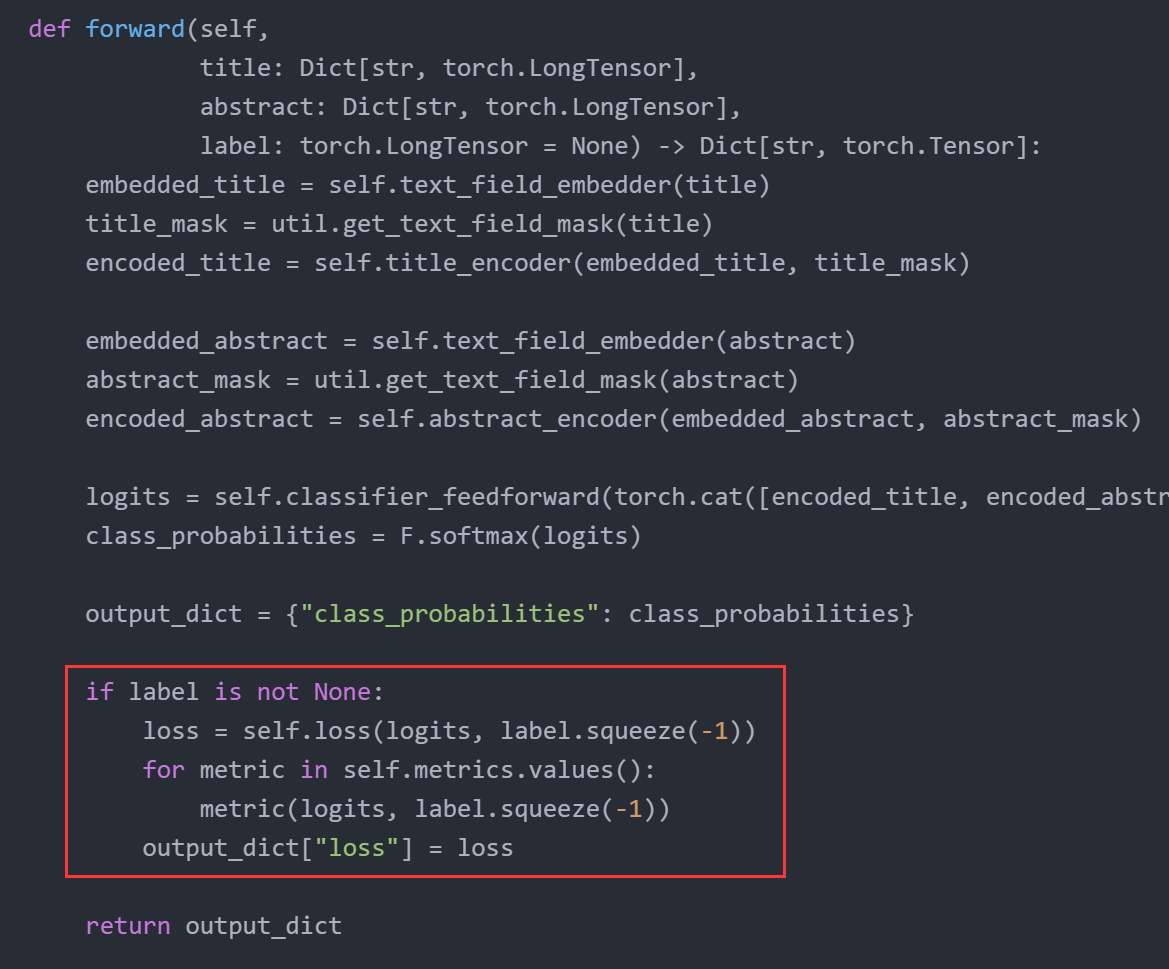
这可能就是为什么要将样本和模型输出作为一个dict来表示的原因。
另外AllenNLP包含加载预训练好的模型,开启一个简单的预测服务的功能,见https://allenai.github.io/allennlp-docs/api/allennlp.service.server_simple.html。
可配置化
AllenNLP中的大部分内置组件都是可配置的,自己实现的DatasetReader、Model的子类也可通过注解赋予其一个特定的名字,如下图所示:
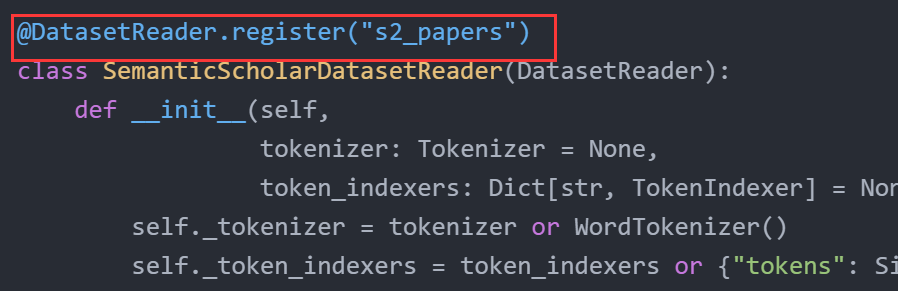
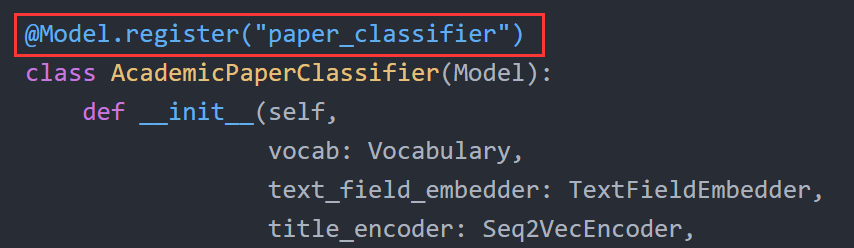
这些名字可以在JSON配置文件中通过“type”字段进行引用。
这样就能通过一个JSON文件对各个组件的实例化参数进行配置,以下面这个模型为例:
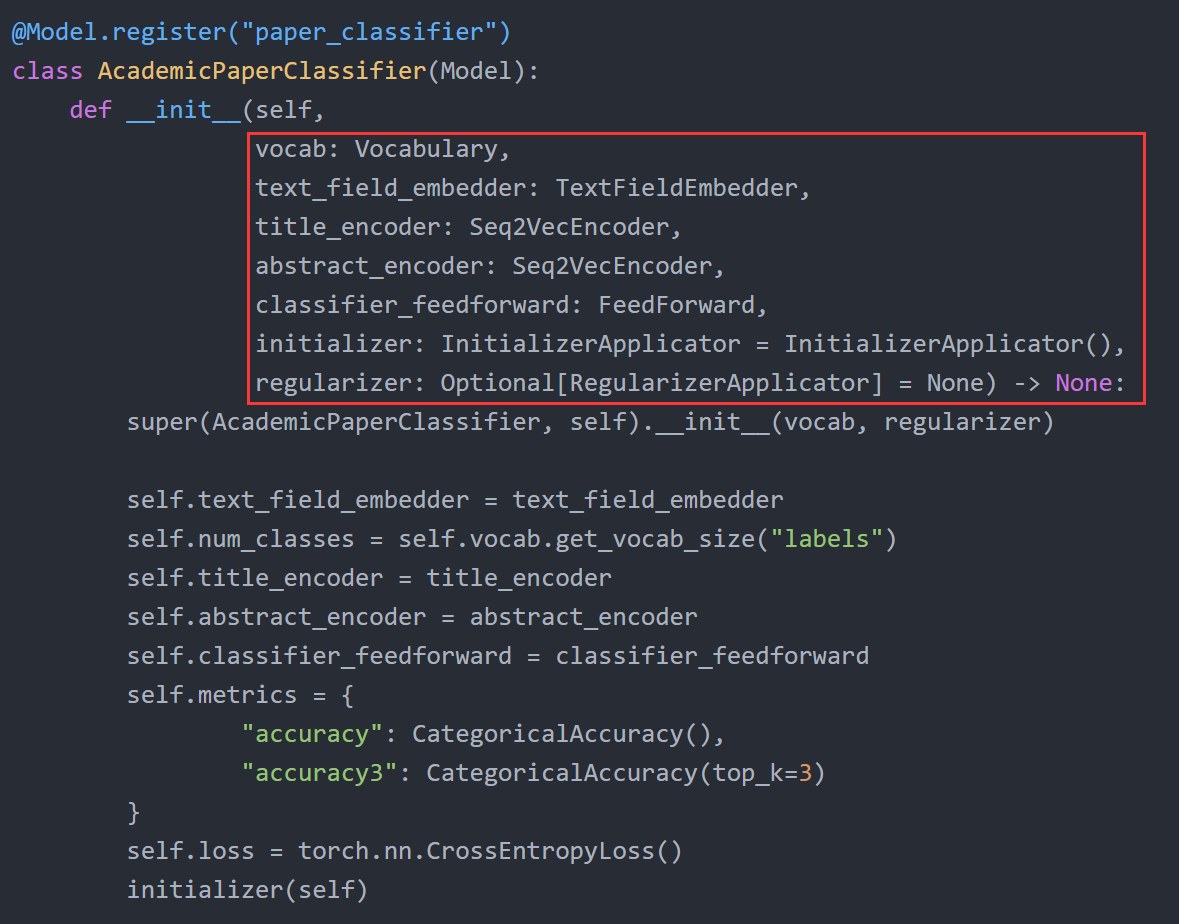
其对应的JSON配置如下:
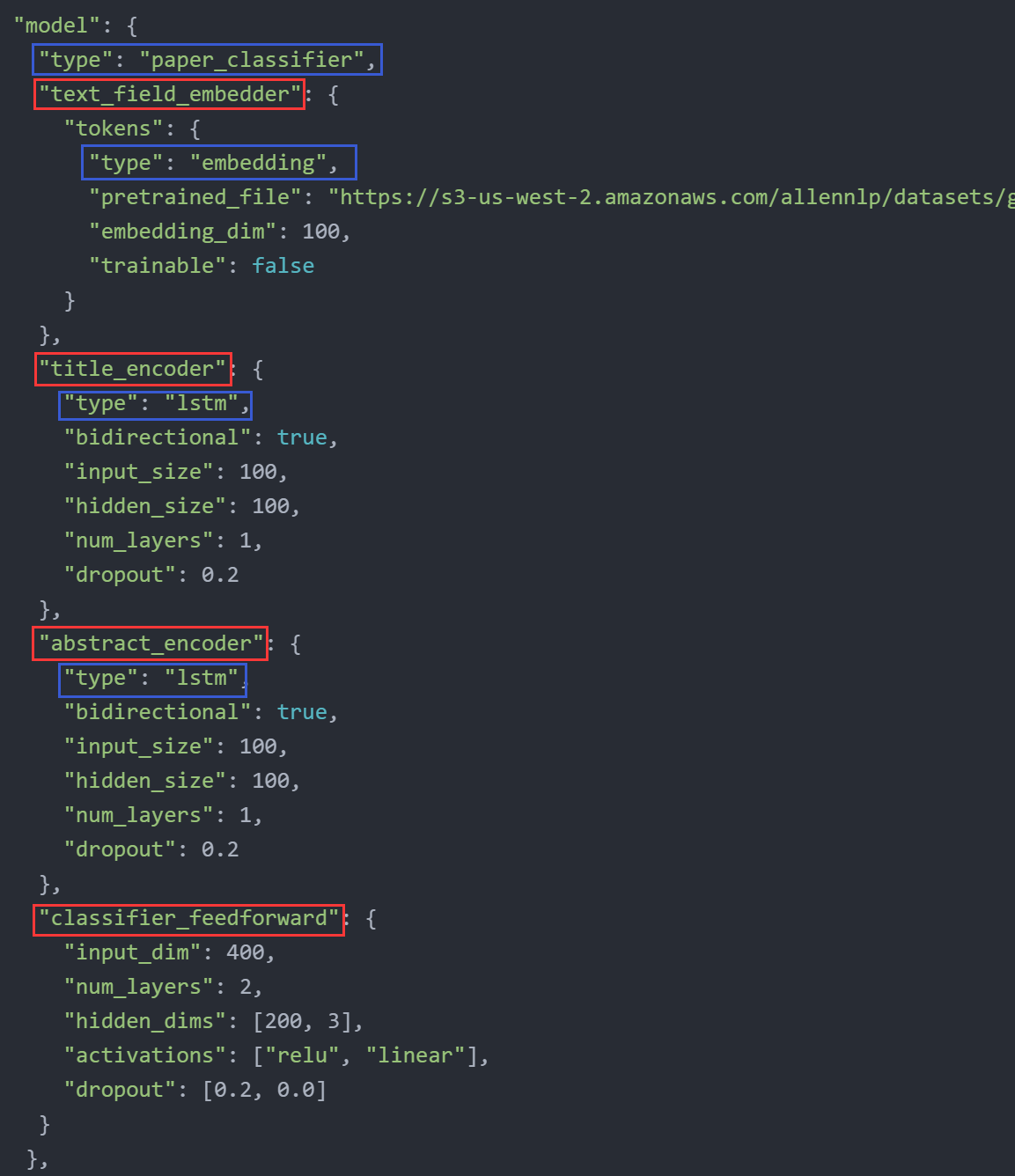
可以看到其构造函数中的各个参数就是对应JSON dict中的字段名,若某参数不是基本类型,则对应的value仍为一个JSON dict,并可通过type字段指明其具体的子类。
下面是一个配置文件的具体实例,其采用jsonnet(json的一种扩展,允许定义局部变量)格式:
1 | // jsonnet allows local variables like this |
随后就可以用AllenNLP自带的命令行工具,使用该配置文件进行训练:
1 | allennlp train tutorials/tagger/experiment.jsonnet \ |
具体见:https://github.com/allenai/allennlp/blob/master/tutorials/tagger/README.md#using-config-files。
通过这种方式训练模型的优点:
- 无需写大量实例化组件的代码
- 实验设定可配置。即对于不同的实验设定,只需要创建多个JSON文件即可(但前提是实现模型是要留出对应的接口、抽象层次),而无需更改模型代码。这样使得实验结果方便追踪
尚没办法优雅解决的事情
这是在PPT中提到的,AllenNLP尚没办法很好进行抽象的情况:

包括:
- 模型参数正则化、初始化
- 包含预训练参数的模型组件
- 复杂的训练逻辑(例如多任务联合训练、对抗训练等)
- 缓存预处理好的数据
- 在测试时扩展词典、embeddings矩阵
如何使用

- 用代码实现一个DatasetReader的子类,将数据文件转化为Instance的stream
- 用代码实现一个Model的子类,将batch of Instances转化为A set of Tensors(训练时需包含loss字段的tensor)
- 使用内置的Trainer,或通过配置文件用命令行工具进行训练、验证
- 使用内置的Predictor进行预测
参考资料
关于上面那个巨长的PPT
似乎是EMNLP2018中,由allenai团队做的分享,PPT的前一半分享了NLP research中的最佳实践方法,后一半就是讲allenNLP中的具体抽象方法了。
PPT中建议的几个点:
-
在需要快速构建模型原型的时候尽量copy代码,之后再考虑重构(if it works);而不是用继承共享代码

-
代码风格要到位(命名、注释等)
-
将模型组件留作参数,而不是写死在代码里

-
Controlled experiments:对实验结果进行追踪很重要
Not good: modifying code to run different variants; hard to keep of what you ran
Better: configuration files, or separate scripts, or something