
Conference from: ICLR 2019
Paper link: [OpenReview] [PDF]
Project page: http://nscl.csail.mit.edu/
本文拟解决的问题
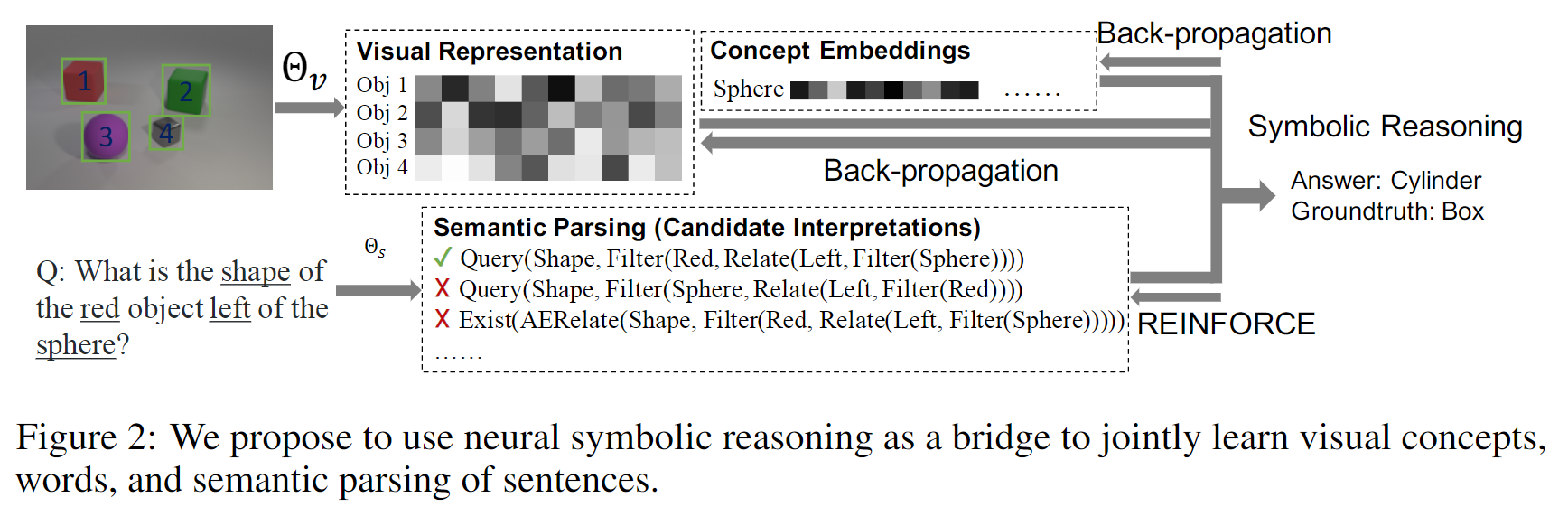
本文要解决的任务是看图问答任务(Visual Question Answering, VQA),如下图所示:

作者认为,人类可以通过看图片和问答对学习到视觉概念。如上图左半部分所示,想象一个没有“颜色”概念的人看到这两幅图时,他应该能识别出这两幅图在视觉呈现上的区别,并且与对应的问答对中的区别对应起来(Red vs Green)。由此从易到难进行训练,就可以在“视觉概念”和“对应的文本语义”之间建立起关联。
本文提出的方法只需要自然地使用配对了的图片、问题、答案三元组进行训练即可(就是论文题目中的Natural Supervision,自然监督)。
本文提出的模型
本文提出的模型叫神经-符号概念学习器(Neuro-Symbolic Concept Learner),能够从配对的图片、问题、答案三元组中联合学习:
- 对图片的视觉感知
- 对视觉概念(如颜色、形状、材质)的表示
- 对问题的语义分析
模型包含三个部分:
- 视觉感知模块,负责从图片场景中提取对象的表示
- 语义分析器,负责将自然语言问题翻译成一个程序(通过Domain Specific Language, DSL表示)
- 程序执行器,负责执行语义分析器给出的程序,得到答案
视觉感知模块(Visual perception)
使用预训练的 Mask R-CNN 和 ResNet-34 来为场景中的每一个Object获取一个表示。由于需要获取到Object在场景中的位置信息,在表示单个Object的时候,同样需要将整个场景作为Context编码进去。
经过这一步之后,场景中的每一个对象都被编码成了一个固定维度的向量。
视觉概念的量化(Concept quantization)
进行视觉推理需要获取每个对象的属性(例如颜色、形状等)。每一个属性类别(Attribute,例如:形状)可以有多个视觉概念(Concept,例如:红色、绿色)的取值。
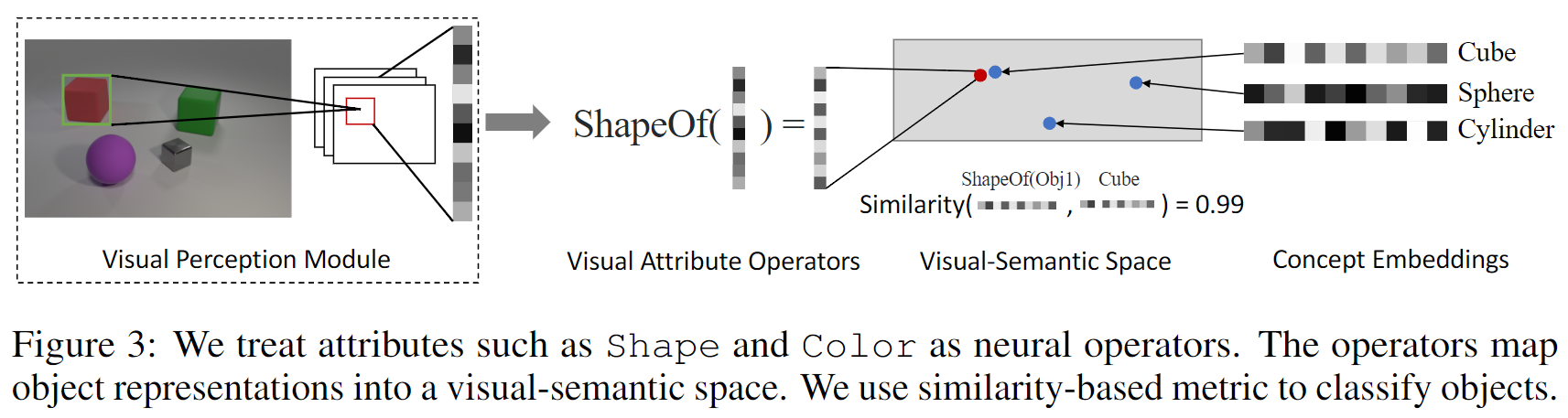
本文中,作者将每一个属性实现为一个神经网络操作(Neural operator)。上图以形状作为例子,该操作接收Object的表示向量,将其映射到另一个向量空间(attribute specific embedding space)中的向量,并且与视觉概念的向量进行相似度匹配:
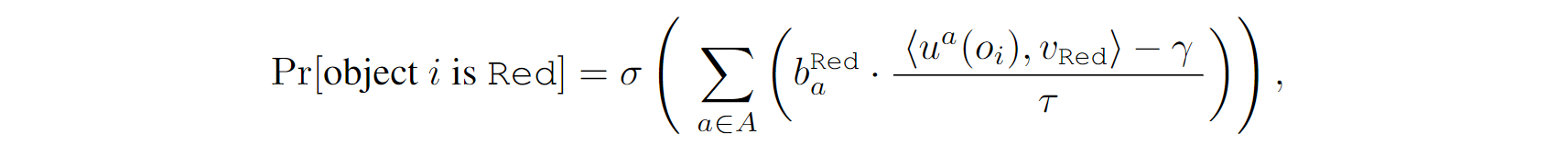
这些视觉概念的向量表示也是联合训练的。
DSL和语义分析(DSL and semantic parsing)

语义分析模块负责将输入的问题解析为一个程序,上面的例子给出了一个示例。这个程序是由该问题的领域特定语言(Domain Specific Language, DSL)中的操作定义的。该问题的DSL定义的所有操作如下图所示:
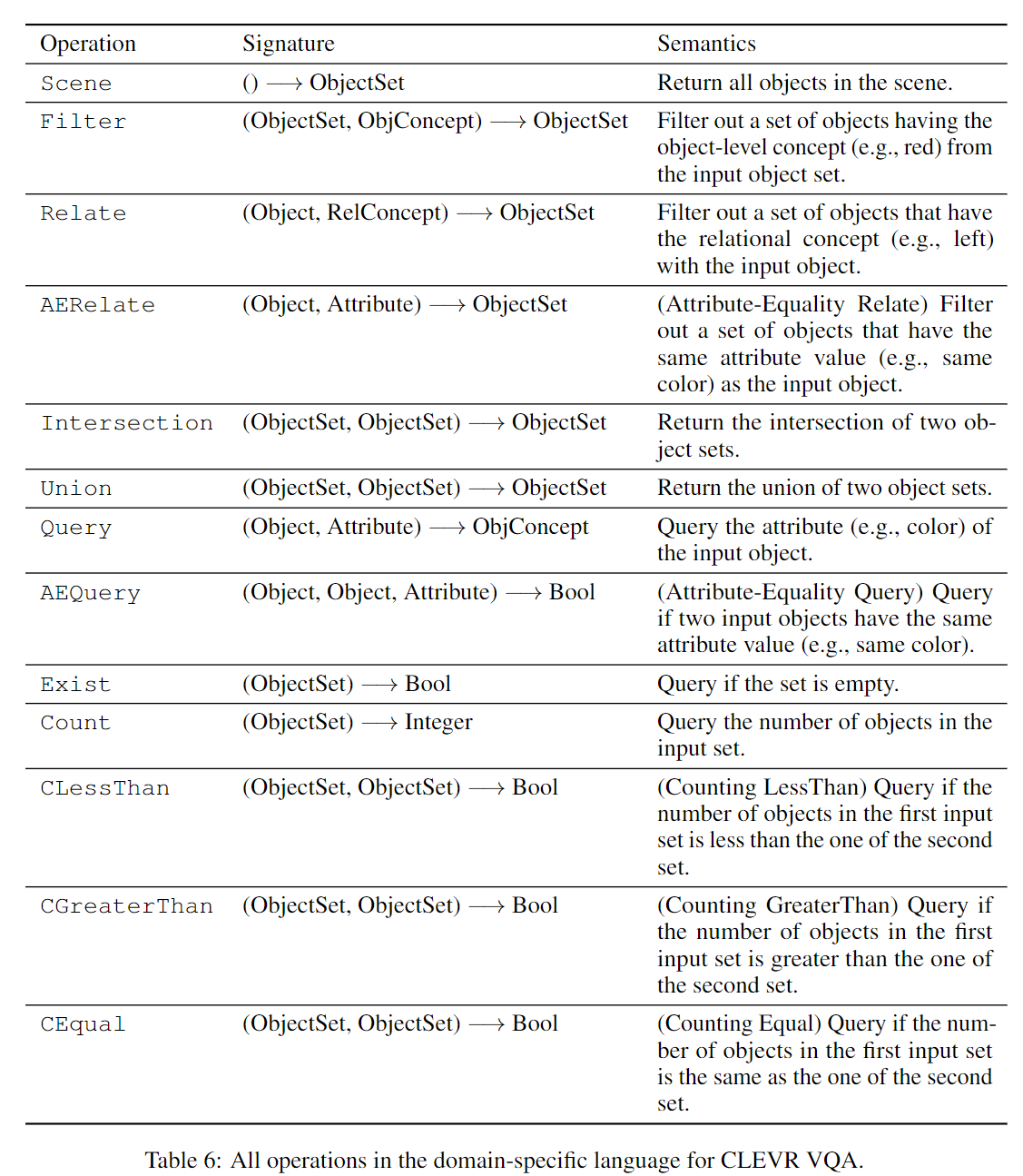
其中的ObjConcept是对象level的视觉概念,例如红色、绿色、正方向、圆柱体等;RelConcept是关系视觉概念,例如Left和Right;Attribute是属性,例如颜色、形状。ObjectSet和Object的含义见下一小节描述。
具体实现上,该模块是一个Sequence to Tree形式的编解码器。首先Encoder负责将自然语言编码成一个固定维度的向量;随后OpDecoder负责产生具体操作(取自DSL),ConceptDecoder负责产生操作需要的Concept或Attribute参数,OEncoder_i负责当前操作的第i个参数表示的编码,如此递归执行。算法流程如下:

这里的是问句中出现过的所有Concept和Attribute的合集,ConceptDecoder将从中选择要输出的Concept或Attribute。
程序执行器
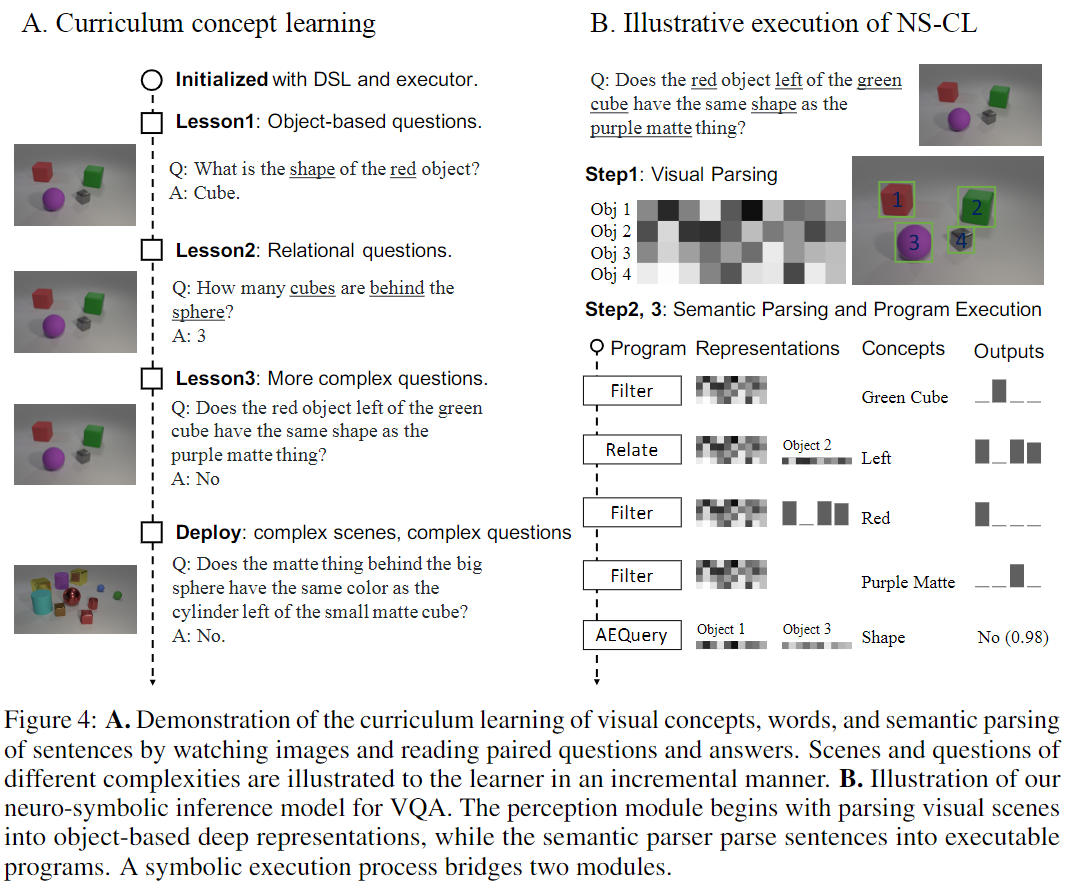
上图(右)给出了程序执行器的例子。
为了说明其执行原理,首先要介绍两种变量类型:Object和ObjectSet类型。前者代表场景中的单个对象,后者代表场景中的若干个对象。
为了让最终结果(即程序执行器最终给出的答案)相对于模型参数(感知模块的参数、概念编码、Attribute操作符)可导,两者均采用基于概率的表示方法:Object类型变量被表示为一个维向量,满足,,其中代表场景中的对象的数目,这里的被认为是第个对象是该变量表示的那个对象的概率;ObjectSet类型变量同样被表示为一个维向量,满足,这里的被认为是第个对象包含在该变量表示的对象集合中的概率。
基于上述设定,DSL中所有操作的实现如下:

其中大部分操作不包含可训练参数,只有包含、、的操作才包含参数。这三个操作符分别代表:判断对象是否属于某个视觉概念(例如红色、正方体);判断某两个对象是否为给定的关系概念(例如在左边、在右边);判断某两个对象是否具有相同的属性(例如颜色、形状)。
训练方法
采用了称为课程学习(Curriculum Learning)的训练方法,即先让模型学习简单的例子,然后慢慢扩展到复杂的场景。如上面的图(左)所示。
训练目标是找到最优参数和,其中是感知模块的参数(包括ResNet-34的参数,属性操作符的参数,concept embeddings),是语义分析模块的参数,使得回答出正确答案的概率最大:
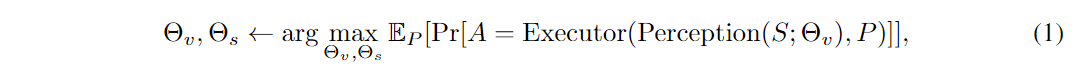
其中代表分析出来的程序,代表正确答案,代表场景,期望 取自所有语义分析模块分析出来的程序。
注意到程序执行器对于感知模块是完全可导的,因此参数的参数计算为:
使用REINFORCE(强化学习)来优化语义分析模块的参数:,其中表示奖励,当答案正确时,否则。