
Conference from: AAAI 2019
Code: https://github.com/zysszy/GrammarCNN
本文要解决的问题
本文拟解决的是代码生成(Code Generation)的任务,即:给定一段自然语言描述,模型自动生成代码片段。例如:给定描述“open the file, F1”,期望模型能自动生成Python代码:f = open('F1', 'r')。
与往常的使用RNN建模不同,本文使用CNN来提取输入特征。作者认为代码片段比传统的自然语言句子更长,因此RNN难以捕获长期依赖;而CNN能够通过滑动窗口捕捉到各个区域的特征,同时CNN具有效率高(可并行训练)、易收敛等特性。
作者提出本文是第一个成功地(完全)采用CNN来做代码生成任务的工作。
相关工作
传统地,代码生成任务被视为是seq2seq任务,使用encoder-decoder结构进行建模,编码器和解码器一般由RNN担任,输入自然语言形式的代码描述序列,输出代码序列。然而,用seq2seq模型建模代码生成任务,忽略了重要的结构信息(例如语法规则的约束),因此生成的代码可能存在语法错误。
为了解决上述问题,研究者们提出了基于抽象语法树(AST)的代码生成。这种方式通过不断预测要展开文法符号所应该采用的规则,依托于树的结构递归地生成程序的抽象语法树,继而获得可执行程序。与上述的seq2seq的代码生成不同,这类方法生成的代码保证了在语法上的正确性。
本文提出的方法就是基于语法规则的代码生成(Python2语法规则表见:https://docs.python.org/2/library/ast.html)。
本文提出的模型
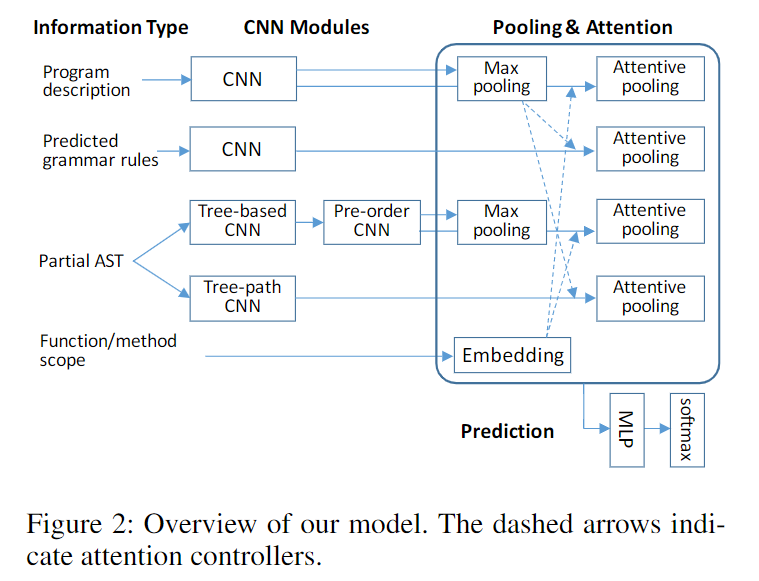
上图给出了本文的模型结构图,其中左半部分为使用CNN对各个输入进行特征的提取;右半部分为使用注意力(attention)和池化(pooling)对特征进行融合。下面对其逐一进行介绍。
基于语法规则的代码生成
该方法即对抽象语法树(AST)进行前序遍历,每次决定使用哪一条文法规则展开一个结点。模型采用自回归(autoregressiveness)的方法构建,即在之前预测的基础上预测下一个要展开的规则。每一个样本的输入为:
- 代码描述信息
- 之前时间步预测的规则
- 当前生成的(部分)抽象语法树
- 当前要展开的结点的位于抽象语法树中的位置
在这些输入的基础上决定展开当前时间步结点采用的语法规则
使用CNN编码输入的代码描述
对于HearthStone代码生成数据集来说,输入(代码描述)是一个半结构化的信息,包括了这张卡牌的名字、属性、描述等,如下图(a)所示,而生成的代码如下图(b)所示。

首先作者将输入的卡牌描述分词,转换为一个token的序列,然后使用word embeddings将其编码成向量序列,其中是输入token序列的长度。随后采用一系列堆叠的卷积层来提取特征,得到特征表示序列。层与层之间采用了ResNet中提出的残差连接(shortcut connections),公式如下:
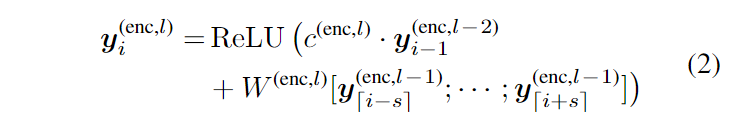
其中,是卷积核参数;通过计算,其中为窗口大小(在实验中采用2);为深度CNN的层数编号。特别的,就是输入的embedding ;表示是否在层级间使用残差连接,对于偶数卷积层,,对于奇数卷积层则为。对前几个和后几个token,使用zero padding。
使用CNN编码之前时间步预测的语法规则
由于是自回归(autoregressiveness)模型,因此需要将之前已经预测出来的语法规则、语法树同样作为特征输入模型(就如同多轮对话中的context一般)。
首先作者将这些语法规则使用embeddings编码,映射成一组向量序列,这个embedding矩阵是随机初始化并且随模型联合训练的。
随后,使用深度CNN来提取出特征,计算方法同上面的(2)式一样。
使用CNN编码预测中的抽象语法树
尽管把预测出来的语法规则作为输入提取了特征,但这些规则是扁平的、序列化的,并不包含树形的层级结构信息,因此对于预测当前时间步的语法规则是不够的。为此,作者又使用了CNN去编码这个抽象语法树的结构。
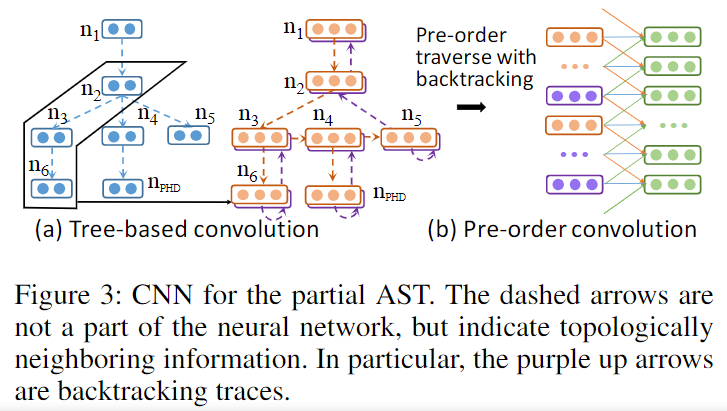
上图给出了这一部分的整体示意图,其中表示当前时间步要预测的结点,它作为一个占位符,也包含在输入的抽象语法树中。具体来说,它又可以分为三个部分:
- 基于树形结构的CNN(Tree-Based CNN)
- 对树结点进行前序遍历的CNN(Pre-Order Traversal CNN)
- 树路径的CNN(Tree-Path CNN)
基于树形结构的CNN
首先每个结点都被编码成了一个向量。设分别代表AST中的某个结点、它的父节点、它的祖父节点的向量表示,通过下面的公式,对AST中每个结点的特征进行提取:
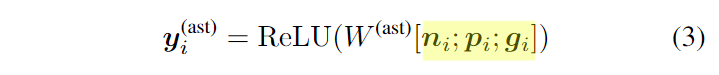
其中是卷积核。AST的前两层将使用一个padding,因为它们没有父节点或祖父节点。
作者认为对于基于语法规则的代码生成而言,当一个规则确定时,它的所有孩子结点也都确定了,对于这些孩子结点来说,其兄弟结点相当于都是确定好了的,因此作者认为兄弟结点相对来说没有父节点(以及祖父节点)重要。因此,相比之前的工作,作者扩大了向上的卷积深度而没有考虑兄弟结点。
对树结点进行前序遍历的CNN
上面基于树形结构的CNN将AST中的每个结点都编码成了一个向量。在这一步中,作者使用一个前序遍历的方式去遍历这棵树,生成向量序列,并对在此向量序列上进行卷积操作(同公式(2))。
由于前序遍历并不唯一地确定一棵树(即存在两棵前序遍历结果相同,但结构不同的树),作者将回溯过程也作为一个结点插入到输出序列,如之前的图(b)所示(橘色代表对节点的第一次访问,紫色代表回溯过程的访问)。
因此,卷积得到的将是一个长度为的向量序列:。其中即为AST中结点的个数。
树路径的CNN
考虑到当前要生成的结点在AST中的位置应该被更显式地表示出来,作者将AST根节点到当前要生成的结点(即图中的)的路径上的所有结点表示也进行了卷积操作,生成,其中为卷积层数,为路径中结点的个数。这一步同样使用公式(2)的计算方法。
基于池化和注意力的聚合
到此为止,模型获取到了四类CNN输出:
- enc:对程序的描述信息
- rule:此前预测的规则
- tree:对AST的遍历
- path:从根节点到预测结点的路径
现在要将这些特征进行融合。作者采用的是max-pooling和attention机制。首先将某些卷积特征进行池化,然后将这个池化后的向量作为query向量,与其它的卷积输出序列计算注意力权重,随后用注意力权重对卷积输出序列加权求和得到一个固定维度的向量,作为最终的向量。
使用何种池化、每一种特征使用何种query向量,如下图中的虚线所示:
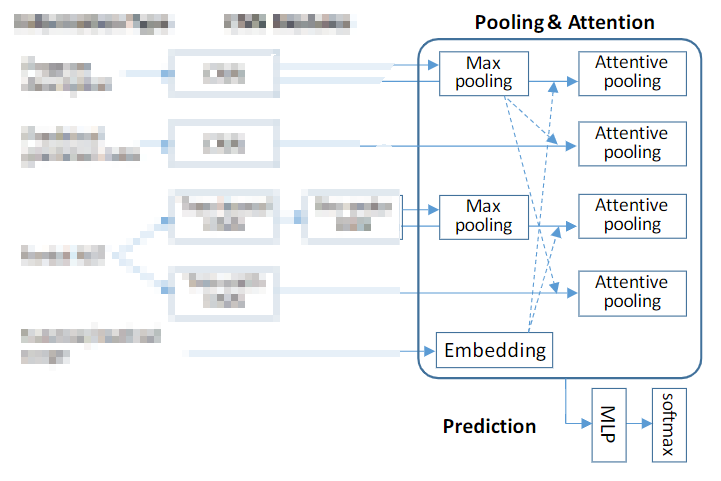
这些是作者通过经验(直觉、假想、实验验证)决定的。
此外,作者还通过将scope(即方法名或函数名)编码后,使用它与代码描述CNN、前序遍历后的CNN进行交互。作者认为这能提供原本模型学不到的特征。当这样的scope存在多个时,作者只采用离当前最近的那一个;当这样的scope不存在时,使用零向量交互。
模型训练
最后,所有这些max-pooling和attentive-pooling的结果都被连接起来,经过一个双层的感知器,将其输出向量作为分类的logits,与ground truth的交叉熵将被作为损失进行训练。
在预测时,使用窗口大小为5的集束搜索,找出使得概率最大的预测序列作为最终的程序。每一步预测中,不合法的语法规则将被忽略。
实验一:HearthStone代码生成数据集
数据集
采用HearthStone数据集,其中包含炉石传说中665张不同的卡牌描述和实现其功能的代码片段(Python形式)。
评价指标
包含三个评价指标:
- StrAcc:在字符串匹配上的准确率
- Acc+:由于模型预测出的部分代码结构正确,但部分变量名与ground truth不同,因此作者又统计了人工修正后的正确率
- BLEU:基于n-grams,作为辅助统计指标
实验结果
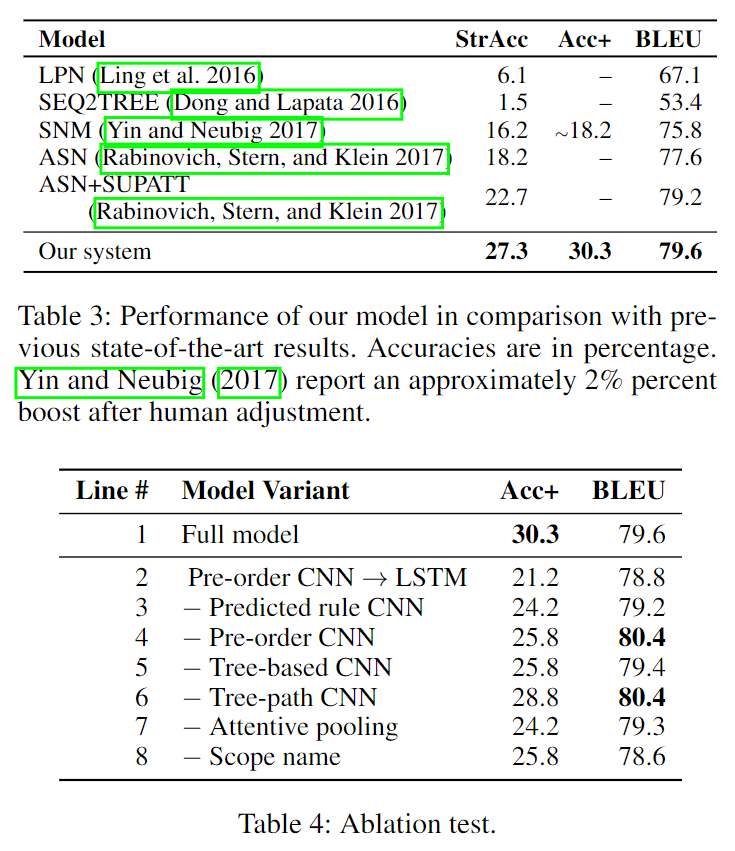

具体分析见原文吧,这里懒得写了。。
实验二:语义分析
语义分析任务可以认为是对领域特定语言(Domain-Specific Language, DSL)进行的代码生成。作者的模型主要针对HearthStone数据集,这个实验作为扩展实验,为了验证模型的可扩展性(generalizability)。
数据集
作者在ATIS和JOBS两个语义分析的数据集进行实验。ATIS数据集的输出是一个λ式(λ-calculus form),如下图所示:

而JOBS数据集的输出是Prolog风格的表达式(Prolog-style form)。
实验结果
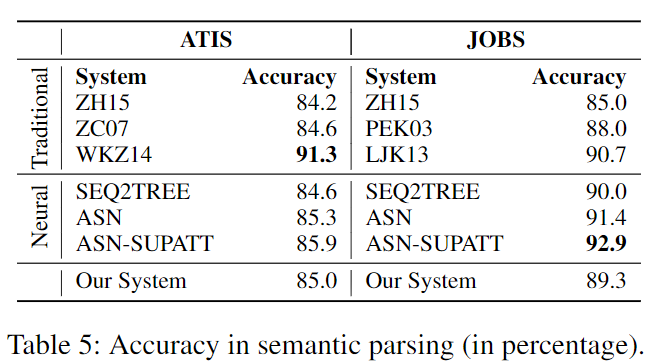
分析同样见原文吧。。