对TextRank算法及其调用方法进行介绍。
从PageRank说起
TextRank算法和PageRank算法类似,都是通过建图对结点的重要程度进行评估,因此这里先介绍PageRank算法。
PageRank是一种经典的网页排序算法,它认为一个网页的质量可以被链接到这个网页的其它网页的质量定义,据此提出了下面的公式:
其中表示某个网页,表示网页的PageRank值;表示链接到的网页,表示网页的PageRank值。表示网页链接出去的总数目,表示阻尼系数。
公式背后的思想就是,网页的价值被其它链接到该网页的网页价值所定义。当某网页被一些高质量的网页所链接的时候,该网页的价值也理应变大;而当某网页很少有网页链接到它,或者链接到它的网页价值均较低的时候,该网页的价值也较低。
注意PageRank是一个迭代算法,即图中每个结点的PageRank值都按照上面的公式进行迭代计算,直到整体趋于稳定。
TextRank
TextRank也和PageRank的思想类似。在PageRank算法中,图的结点为网页页面;而到了TextRank,结点就变成了某个词语。在TextRank算法中,基于单词在N-gram的中的共现关系进行构图:
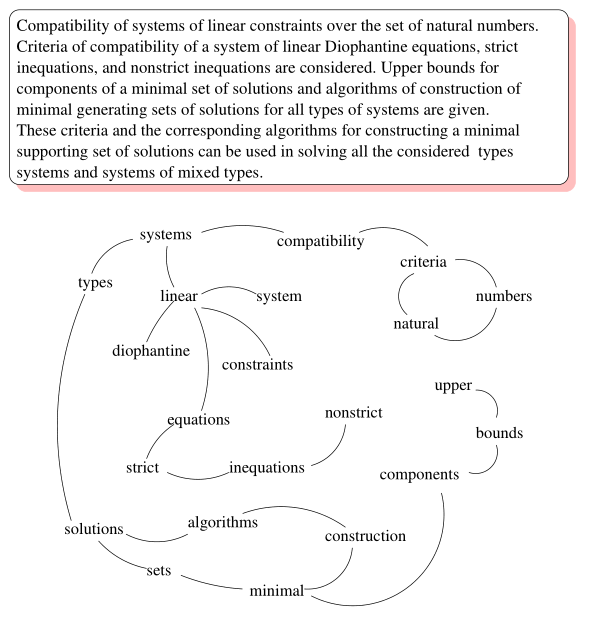
考虑到每个词对都会有不同的共现次数,将PageRank中的公式修改如下:
和PageRank算法唯一的不同在于引入了权重表示第个词和第个词之间的共现频率。
使用TextRank提取关键词的算法流程
TextRank的算法整体流程如下:
- 对给定的文本T进行分句
- 对于每个句子进行分词和词性标注,过滤掉停用词,只保留指定词性的词语,如名词、动词、形容词这类实义词
- 基于词共现关系(N-gram)构建无向图
- 根据上面的公式,迭代计算各个结点的TextRank值,直至收敛
- 对每个图结点(单词)根据TextRank值进行排序,选择出最重要的K个词,作为候选关键词
- 对于这K个关键词在原文中进行标记,若构成相邻词组,则将这些关键词合并成多词关键词
如何使用(现成的调用工具)
在网上找到了基于TextRank算法实现的工具包summa,可通过pip安装:
1 | pip install summa |
使用方法如下,输入一段文本段落,自动提取出关键词:
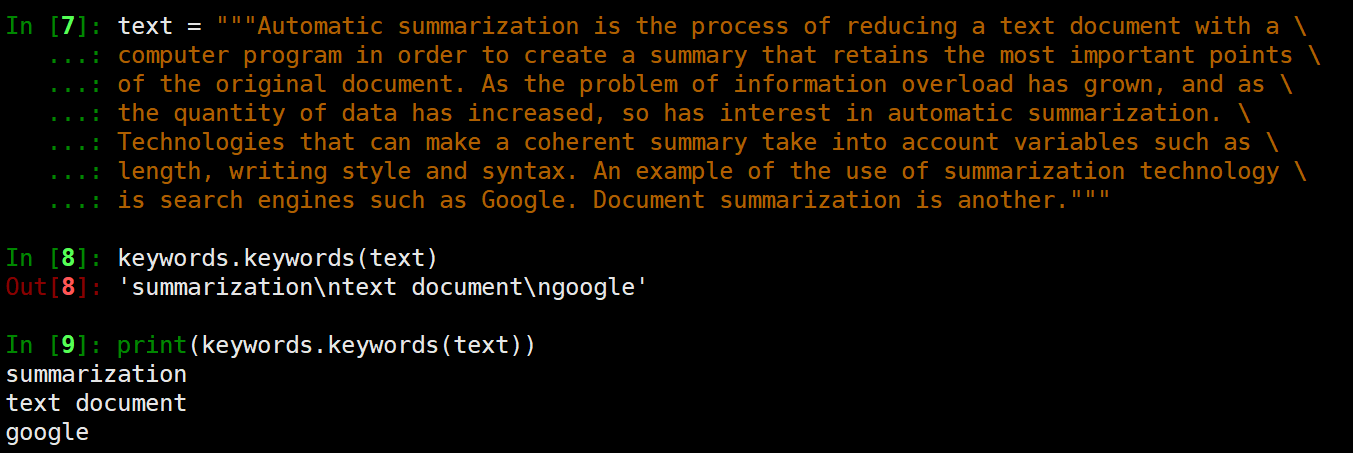
此外还可以通过参数ratio指定关键词数目占全文比率;通过参数words指定关键词数目(大致数目)等:
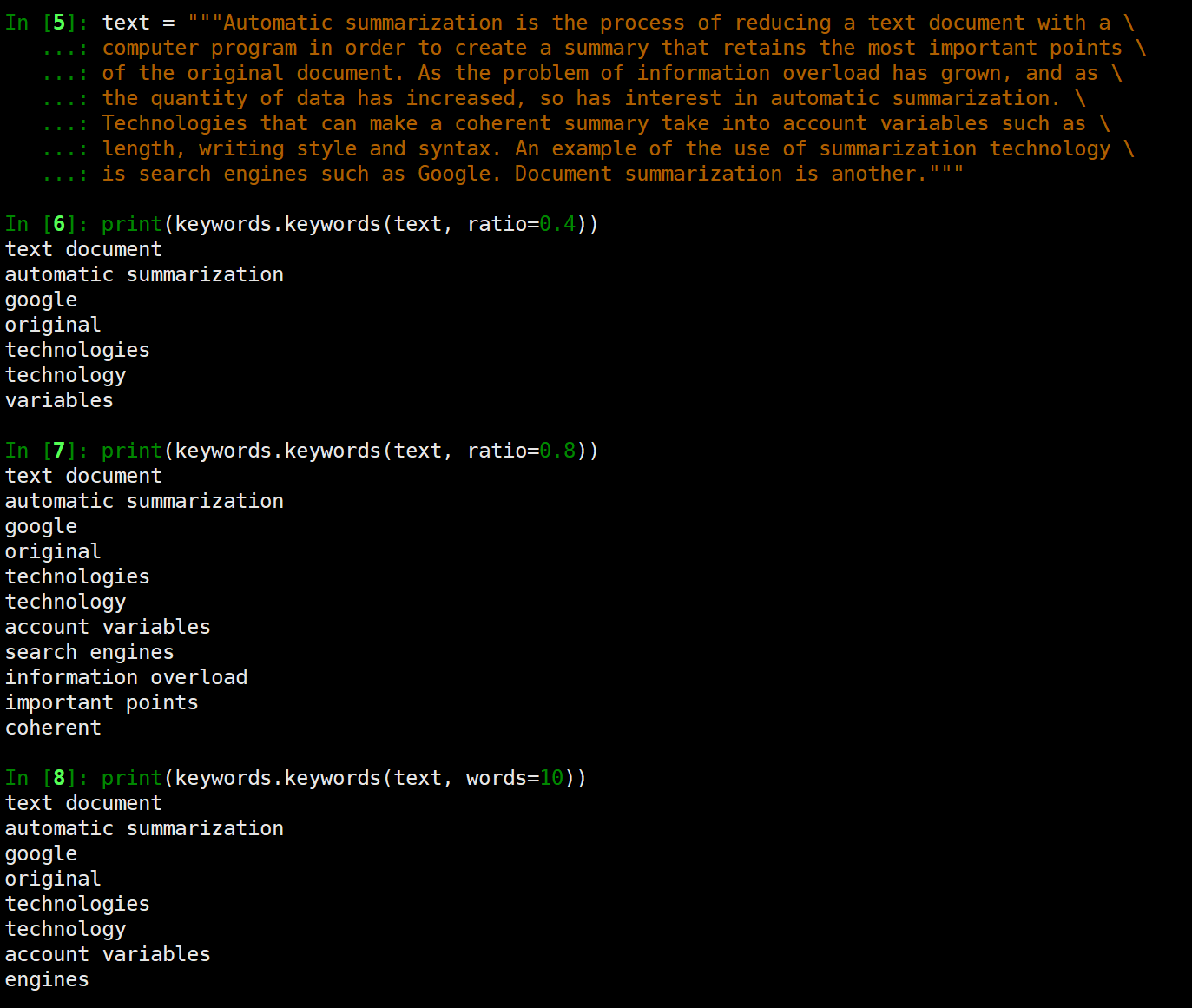
通过设置参数scores=True可以输出每个关键词的分值: