
Conference from: ACL 2019
Paper link: Arxiv
Project page: Github
Introduction
句子简化(Sentence Simplification)或文本简化(Text Simplification, TS)任务,意图在维持一个句子表义不变的情况下,降低该句子的复杂度,从而更好地帮助对该语言掌握程度较差的人(例如儿童、第二语言学习者)阅读。下面是几个句子简化任务的示例(摘自WikiSmall数据集)。

受到机器翻译模型成功的影响,目前大多数的句子简化模型都将其视为一个单语的类翻译任务,使用类似机器翻译的seq2seq模型结构,从“复杂句-简单句”的句子对中隐式地学习如何简化一个句子。然而,由于在句子简化任务中,很大部分的句子成分是保留的,这样就使得模型在学习过程中倾向于保留句子成分,从而生成和原始句子一模一样的句子。
本文提出了一种显式对句子编辑操作进行建模的神经编程解释器(Neural Programmer-Interpreter, NPI)模型。模型通过显式地预测编辑操作,例如ADD、DELETE、KEEP,来完成句子的简化,下图给出了模型在不同数据集上的一些运行示例。

作者认为,将“复杂句-简单句”中不变的部分改为使模型预测“KEEP”,能够让模型更关注于其中变化的部分。同时这种方法,相比于基于机器翻译的黑盒模型,有着更好的可解释性。本文的贡献有以下两个方面:
- 提出了端到端训练的、显式对编辑操作进行建模的模型,而非基于机器翻译的隐式学习句子简化模型;
- 设计了基于神经编程解释器的模型结构,包含一个程序生成(programmer)模块和一个解释器(interpreter)模块,共同模拟对句子进行编辑的过程。
Model
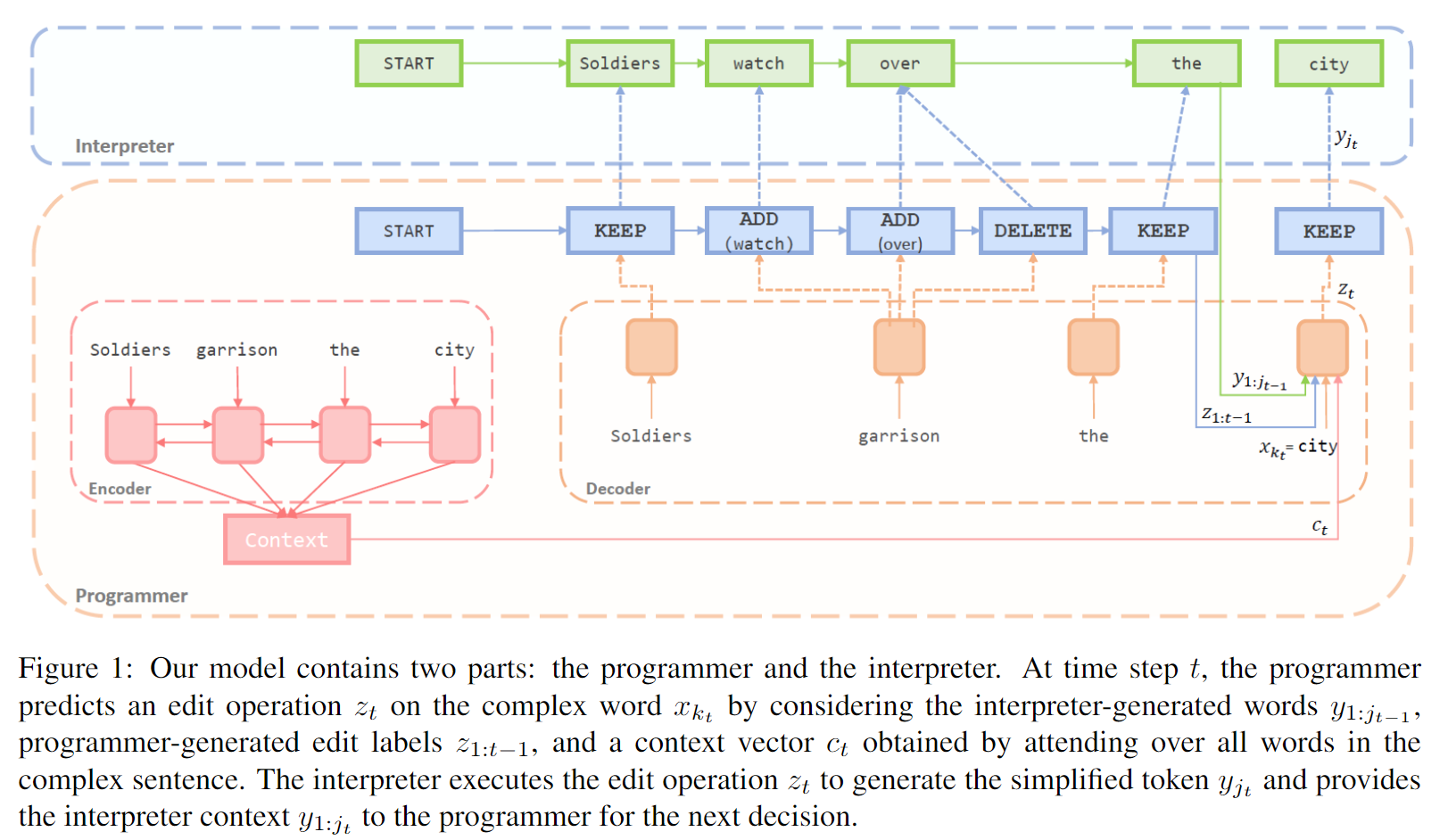
本文提出的模型叫EditNTS,其结构如上图所示。模型包含两个部分:Programmer部分负责生成编辑操作;Interpreter部分负责维护编辑后的序列(即负责执行编辑操作)。
概述
作者定义了四种编辑操作:
- 添加词语:
ADD(W) - 保留词语:
KEEP - 删除词语:
DELETE - 完成编辑:
STOP
作者在原有语料库词汇表的基础上额外添加了KEEP, DELETE, STOP三个词语。
模型需要建模的条件概率分布为:
在每一个时间步,Programmer预测一个编辑操作(即扩充后的词表中的一个token)。此时针对的原始句子中的词语为。Programmer输出编辑操作的决策基于以下信息:
- 编辑后的部分句子:
- 之前时间步生成的编辑操作:
- 完整的复杂句:
下标含义说明
总共有三个序列:复杂句(用表示),简单句(用表示)以及编辑序列(用表示),它们在生成第个编辑操作时的对应下标(指针)分别为:、、。和可理解为的两个函数,其中表示之前预测的KEEP和DELETE操作的数目;表示之前预测的KEEP和ADD(W)操作的数目。
Programmer
首先对于原始句子及其POS标签,用word embeddings编码成向量,随后用LSTM进行编码:
其中和分别表示两个embedding操作。
随后使用当前待编辑的词语对应的隐藏向量作为query和所有时间步的隐层向量做注意力得到复杂句的上下文向量:
使用了一个代表编辑操作的LSTM生成当前时间步的编辑向量(这里的是Interpreter部分生成的向量,之后会说明):
最后使用这一编辑向量生成预测:
Interpreter
Interpreter包含两个部分:
- 不包含参数的编辑操作执行器,它将Programmer生成的编辑操作应用于词语,生成一个新的词语,其包含下列操作:
- 执行
KEEP/DELETE来保留/删除当前词语,并且将编辑指针指向下个词语 - 执行
ADD(W)来添加一个新的词语W,编辑指针不动 - 执行
STOP来退出整个编辑过程
- 执行
- 一个LSTM,对编辑后的部分输出句子进行编码,输出,以帮助预测下个编辑操作。
生成标准的编辑操作序列
由于模型预测的是编辑操作,因此需要根据简单句和复杂句生成标准的编辑操作作为监督。作者采用了动态规划(DP)算法计算两者间的最短编辑操作(即编辑距离:Levenshtein distance,但这里不包含替换操作)。当有多个编辑序列同时匹配时,作者规定ADD操作始终在DELETE操作之前。通过这种方法,可以生成唯一的编辑序列,如下图所示:

Experiment
Dataset
作者在三个句子简化的数据集上进行了实验:
- WikiSmall
- WikiLarge
- Newsela
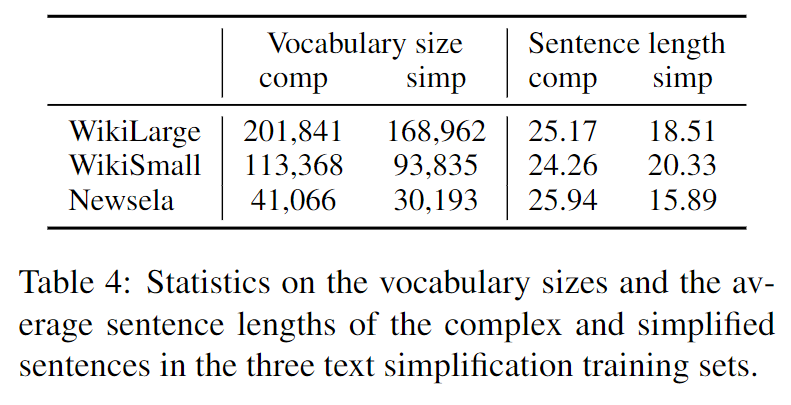
前两者基于维基百科上的文章;后者基于新闻文章。下面给出了数据集的统计信息
评价指标
- 自动评价指标
- FKGL,用于评价系统输出的可读性(readability),越低表示输出越简洁可读
- SARI,计算系统输出和标准句在add、delete、keep三种编辑操作上,N-gram(N=1,2,3,4) F1值的算术平均
- 人工评价指标
实验结果
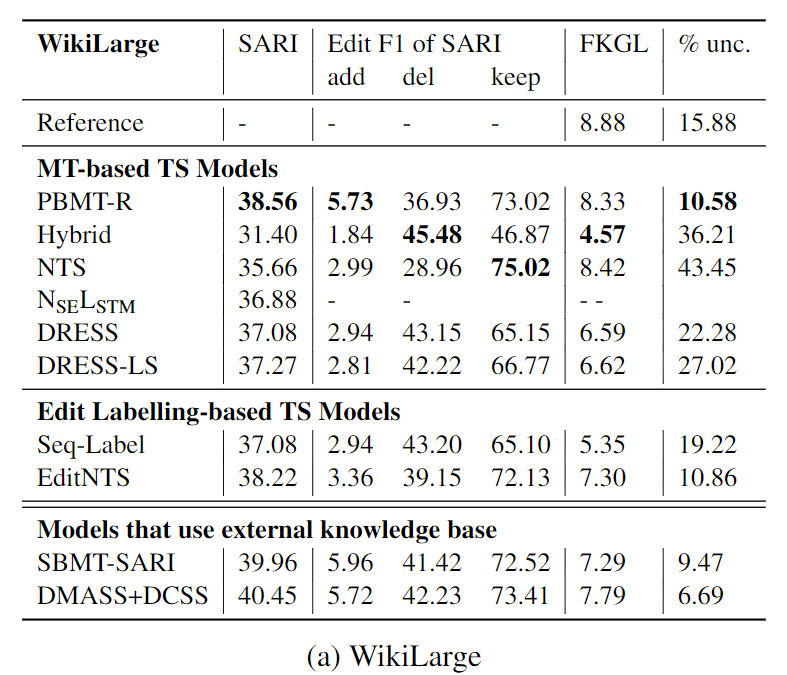
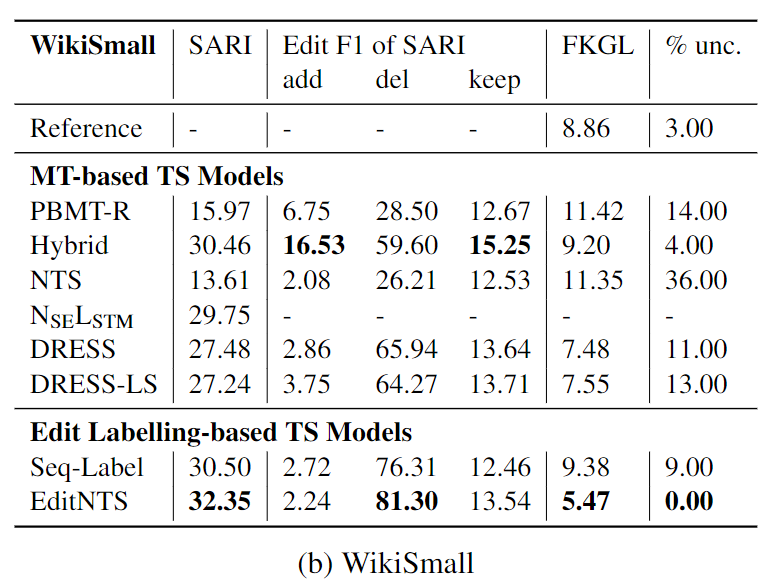
自动评价指标
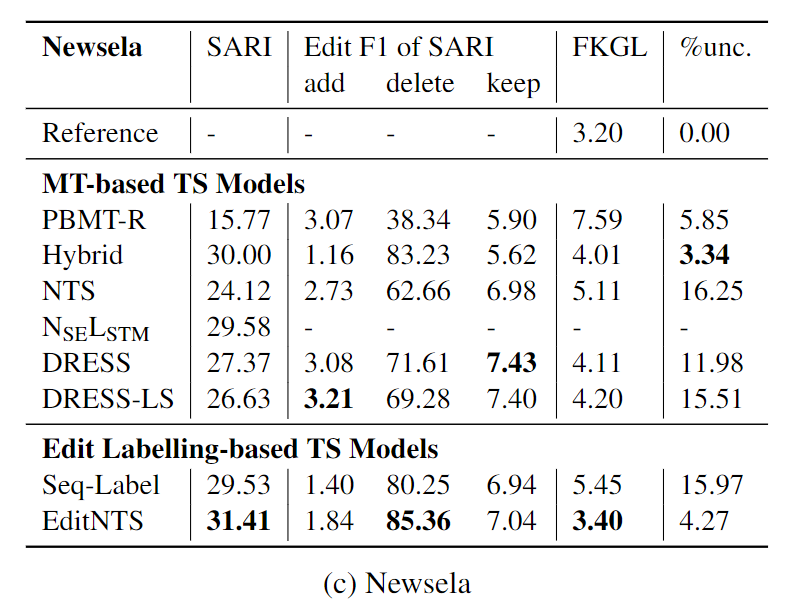
人工评价指标
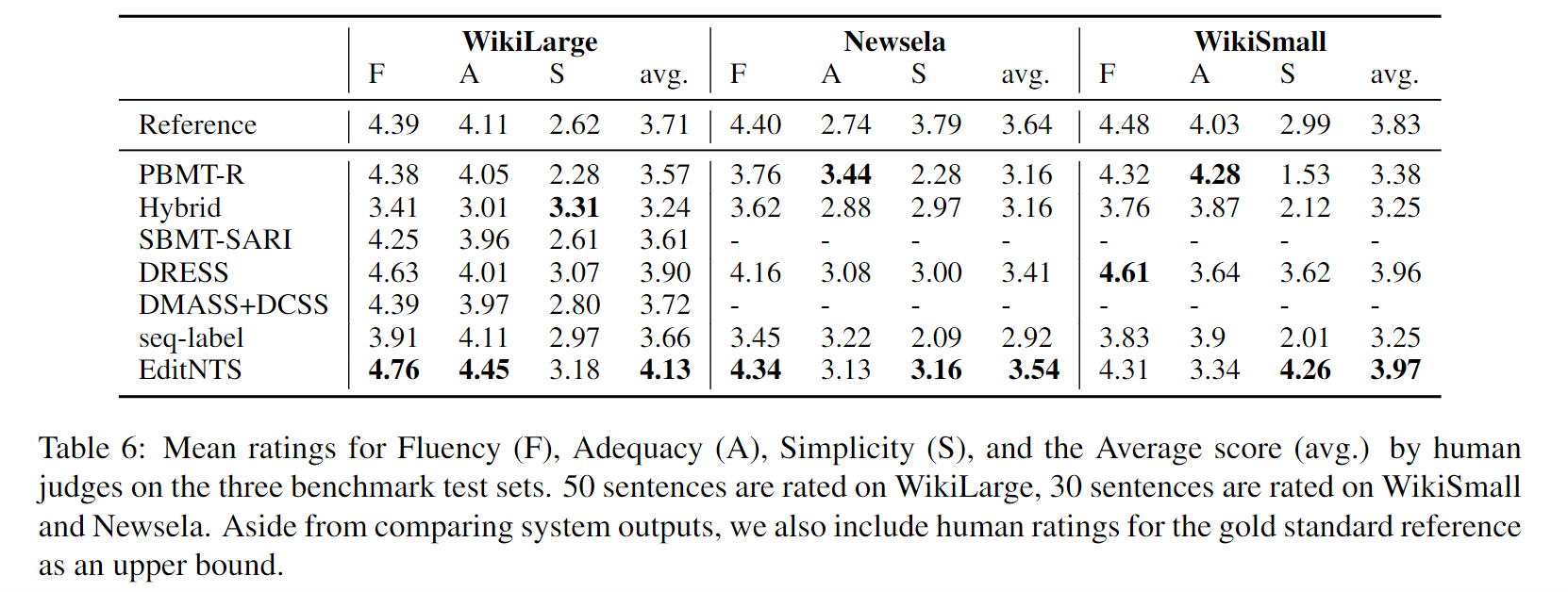
Conclusion
本文提出了一个适用于句子简化任务的基于神经编程解释器(NPI)的模型。其中Programmer负责生成编辑操作,Interpreter负责执行编辑操作,生成简单句。本文提出的模型超越了之前基于机器翻译的SOTA模型,展示了显式学习编辑操作的有效性。与传统的基于机器翻译的黑盒模型相比,本文提出的模型更具有解释性,并且更加可控。