Conference from: NIPS 2017
Paper link: [PDF]
Introduction
在Transformer提出之前,在机器翻译或语言模型任务中用来建模序列的主流方法都是采用RNN,然而由于RNN的按时间步展开的特性,使得其无法并行化。此前,研究者们为了解决RNN的循环特性导致的不可并行化问题,提出了多种模型,包括ByteNet、ConvS2S等。然而这些模型都基于CNN,存在难以建模远距离依赖的问题。本文提出了Transformer结构,完全基于注意力来编码输入和计算输出,而不依赖于序列对齐的循环或卷积神经网络。
Model
本文仍然遵循了编解码器的结构。编码器负责将输入 编码成一组连续的表示 ,然后给定 ,解码器负责生成输出序列 。本文的总体模型结构如下图所示:
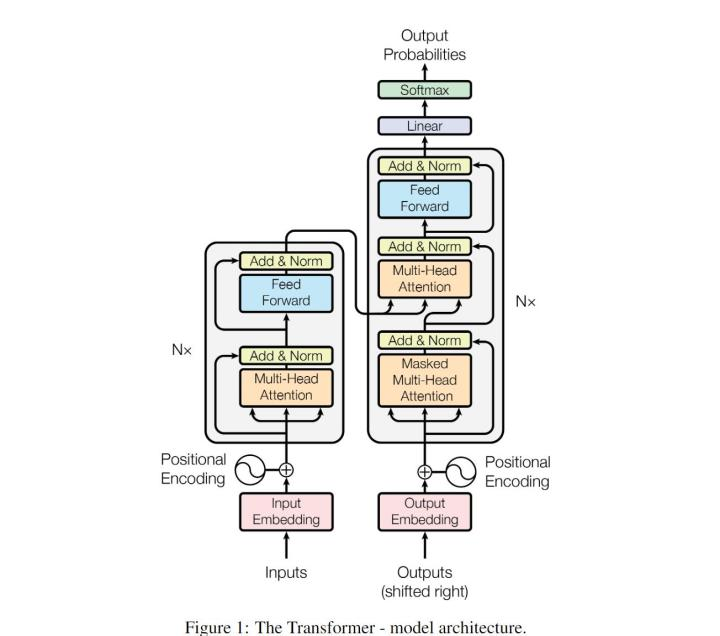
Encoder
编码器是 层相同结构的堆叠,每一个层包含两个子层:多头自注意力和一个简单的element-wise前馈神经网络。每个子层中间都采用了残差连接 + 层归一化,即每一个子层的输出为 ,其中 代表这个子层本身(多头自注意力或前馈神经网络)。其中,所有子层输出向量的维度均为 。
Decoder
解码器端的结构同样是 层相同结构的堆叠,整体结构和编码器类似,不同的是这里加入了第三个子层,使用自注意力的结果作为Query,编码器的输出作为Key和Value进行交叉注意力。此外,这里的多头自注意力部分加入了mask,从而将当前预测位置之后的所有位置mask掉(将点积结果设为负无穷),以保留模型的自回归的特性。
Attention
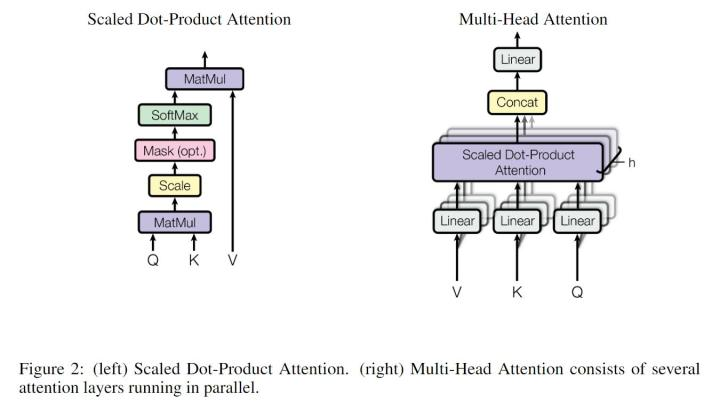
Scaled Dot-Product Attention
注意力机制可视为是一种软查询。给定 维的queries和keys向量,以及 维的values向量,本文提出的Scaled Dot-Product Attention(上图左)计算输出如下:
其实就是传统的自注意力加上了缩放( ),作者观察到当 很大时,点积的结果会比较大,就使得输出落在softmax函数中比较偏离中心点的位置,使得梯度很小。归一化能够帮助点积的输出回到中心位置。
Multi-Head Attention
在Scaled Dot-Product Attention的基础上,作者提出了多头注意力机制,如上图右所示。具体操作即使用一组映射矩阵: ,分别将queries、keys和values进行映射,每一个 对应了其中的一个head:
这里的 即上文中的Scaled Dot-Product Attention。随后所有head的输出将被拼接,再使用一个映射矩阵,映射回原先的维度 :
其中 , 为head个数。实验中,采用的中间维度为 。这样能够使得多头注意力模块的参数总量和原先的单头注意力相当。
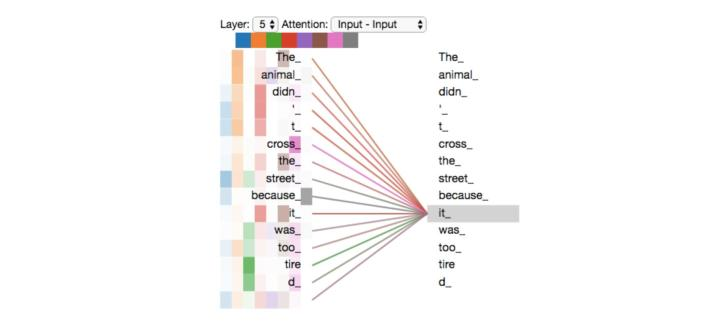
以下是来自Illustrated Transformer的可视化展示:
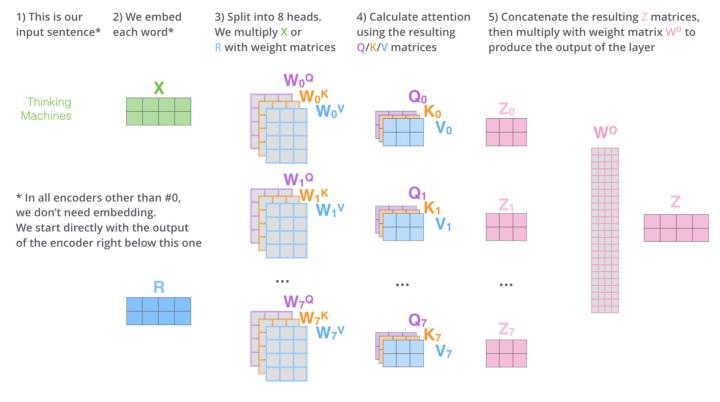
作者认为,多头注意力使得模型有能力学习到不同子空间的表示。而单头注意力,相当于将所有这些不同子空间取平均了,因而抑制了这一能力:
Position-wise Feed-Forward Networks
在多头注意力之后,作者将每个时间步的输出分别过一个前馈神经网络。它是两个线性层的组合,中间使用ReLU激活函数:
其输入和输出向量的维度都是 ,而中间隐层的维度为 。这个全连接层在每一层的不同时间步是共享的,但是在不同层是独立的。
Positional Encoding
由于模型完全不包含循环或卷积,因此为了让模型感知序列的顺序信息,需要将位置信息编码进去。作者在编码器和解码器的embedding层之后加入了位置编码(同样是512维):
其中 表示位置, 表示生成向量的第 个分量。
整体翻译过程
第一个阶段为编码阶段:输入的token将首先通过Embedding矩阵,嵌入到 维的向量空间。随后每一个token的word embedding将与512维的positional encoding求和,送入transformer block。
在编码器的每一层transformer block中,向量序列将首先进行多头自注意力,结果进行残差连接和LayerNorm后,再对每一个时间步的向量过一个两层的前馈神经网络,同样进行残差连接和LayerNorm。这样重复6层后,得到的向量序列即作为上下文感知的中间向量 。
第二阶段进入解码阶段:在每一个时间步,翻译后的句子经过Embedding(同样包含position encoding)之后,被送入解码器的每一层transformer block。
在解码器的每一层transformer block中,向量序列首先进行多头自注意力(包含mask),随后与上下文向量 进行多头交互注意力,最后经过前馈神经网络。6层后的输出结果进行线性映射和softmax之后,预测出这一时间步的输出token。
以下是来自Illustrated Transformer的可视化展示:
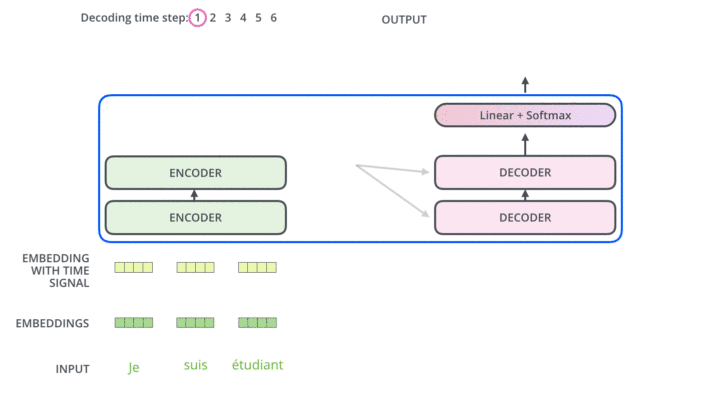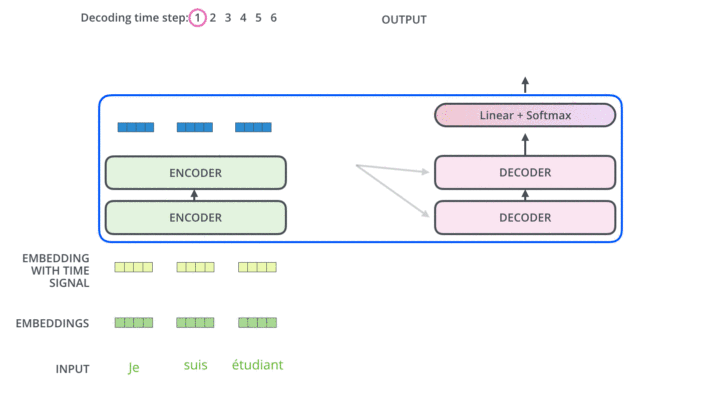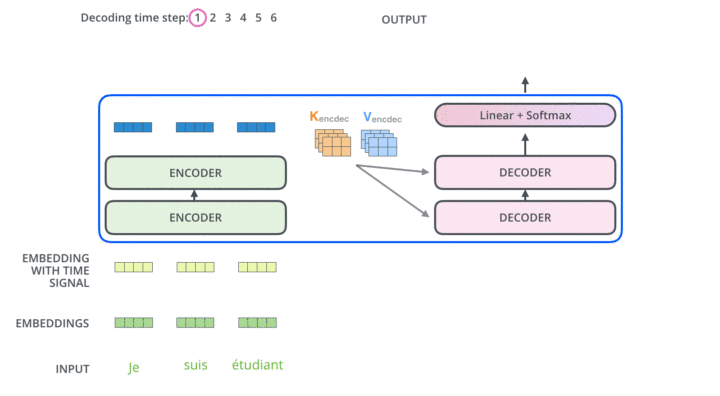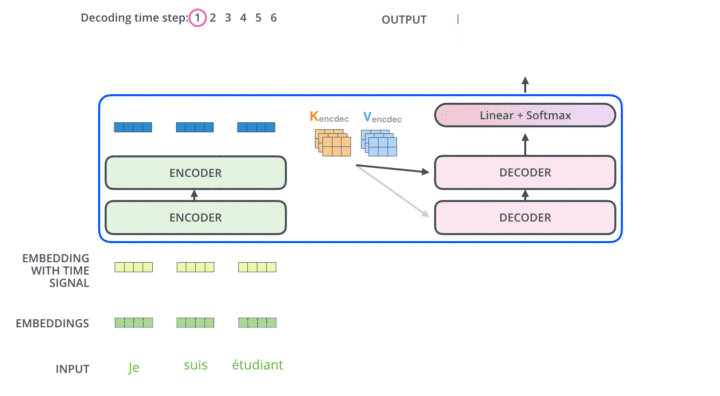
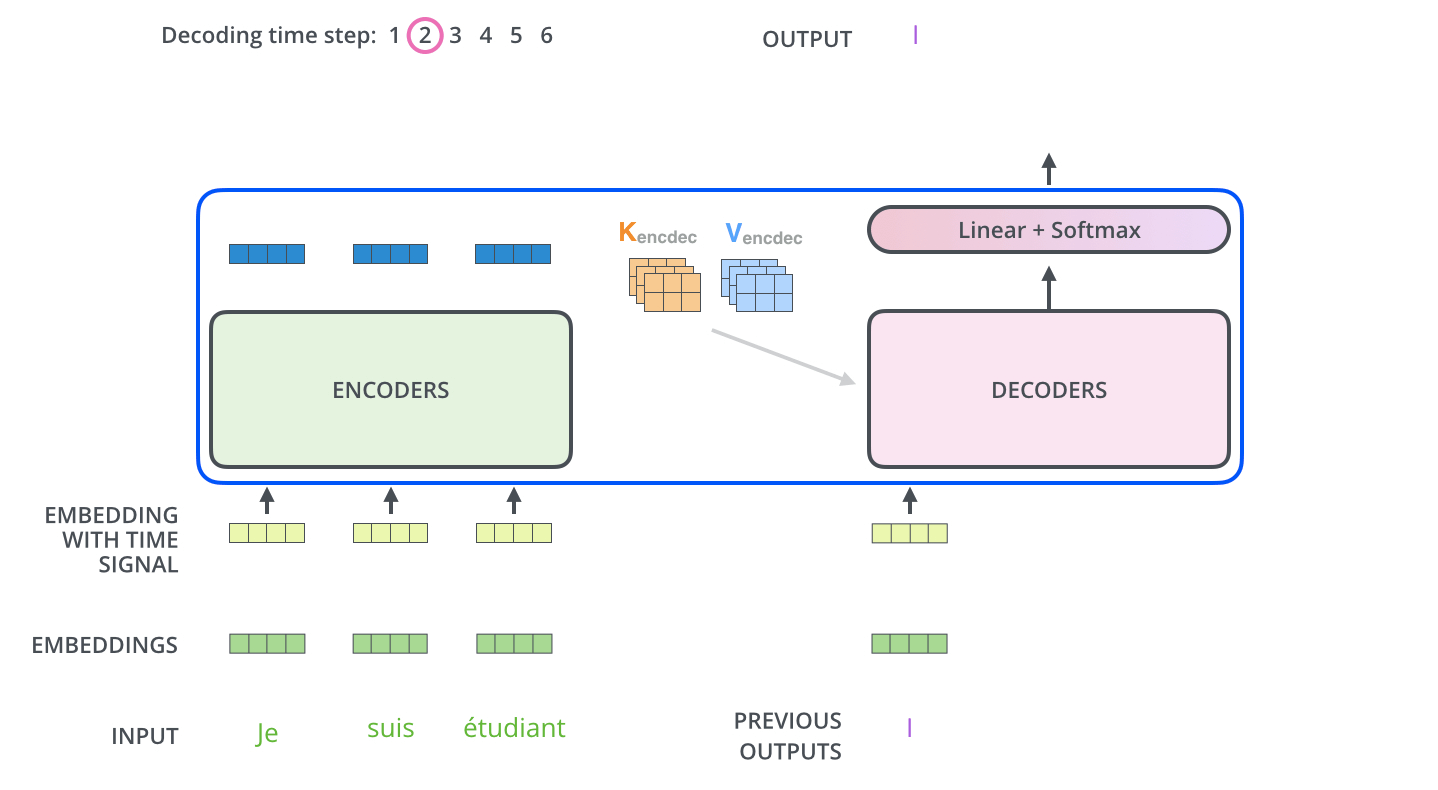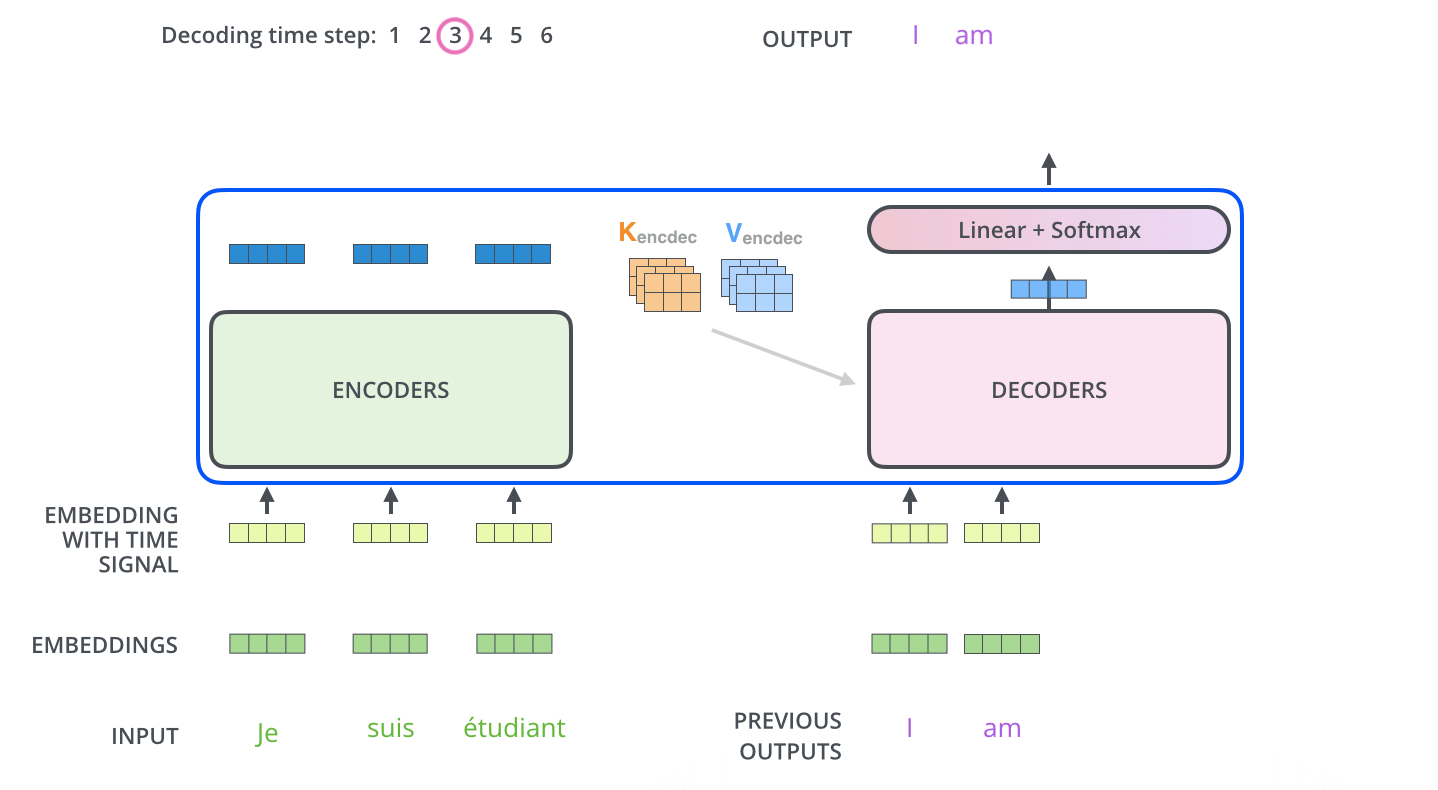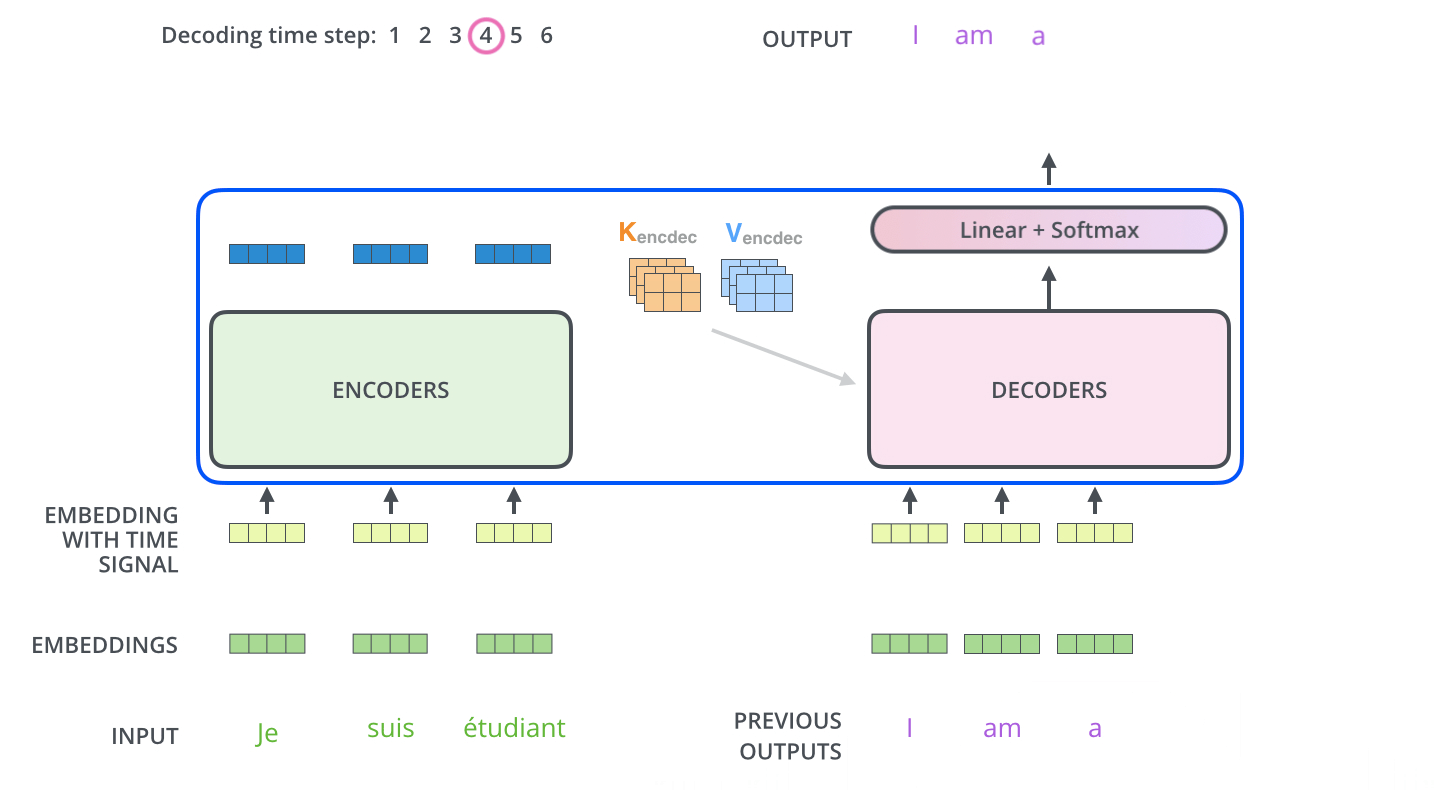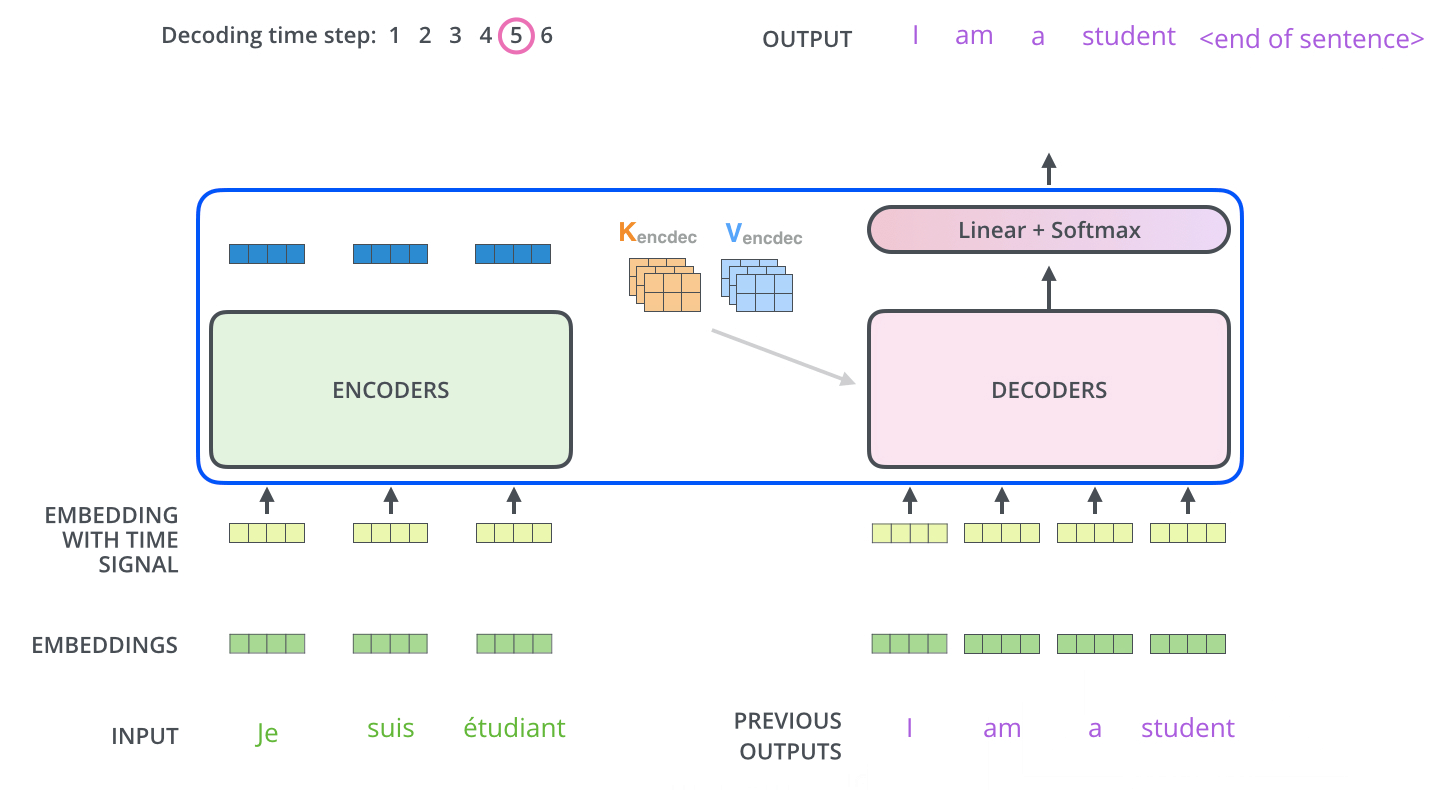
Experiments
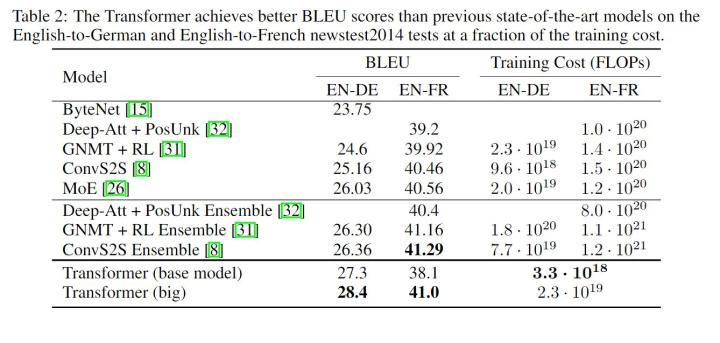
作者在WMT2014English-German和WMT2014 English-French数据集上进行训练,在英语到德语的数据集上取得了SOTA。并且可以看到,模型的训练成本较其它机器翻译模型低。
Transformer的应用
1. 在任务的特定模型中,作为上下文相关的编码器或解码器
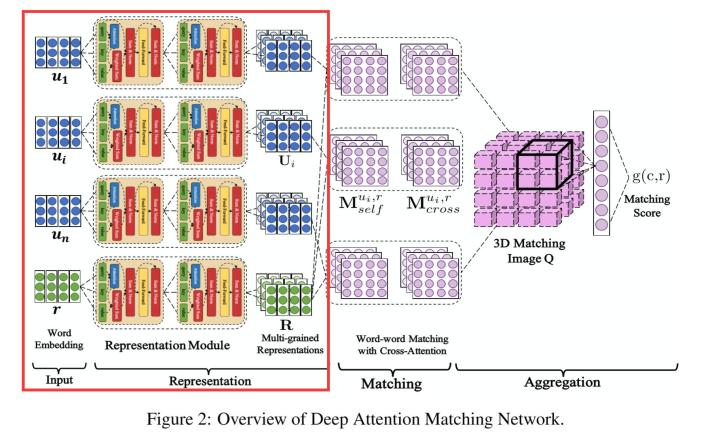
用来建模序列,生成上下文相关的句子表示。例如在论文《Multi-Turn Response Selection for Chatbots with Deep Attention Matching Network》中,Transformer被用来提取word embedding序列的上下文表示,如下图所示:
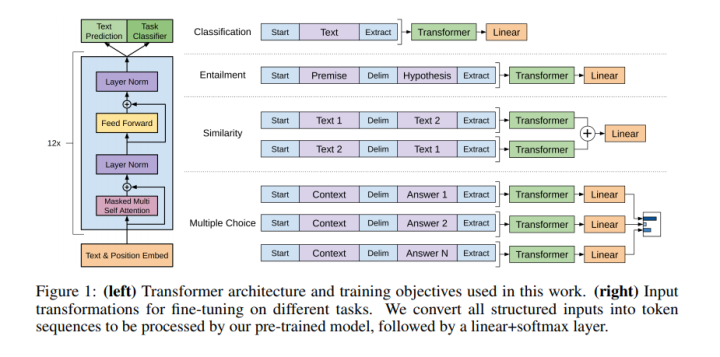
2. 作为预训练语言模型中的特征提取器:OpenAI GPT、BERT等
OpenAI GPT:
BERT: