
Conference from: EMNLP 2019
Paper link: [PDF]
Introduction
本文意图解决的是文本摘要任务。指针生成网络目前已经成为了目前的文本摘要模型的标准。然而指针生成网络往往受限于以下两个问题:
- 首先,指针只能复制精确的单词,而忽略了可能的变形或抽象,这限制了它捕获更丰富的潜在对齐的能力;
- 其次,复制机制授予了模型强烈的复制导向,使得大多数的句子都是通过简单复制源文本产生的。
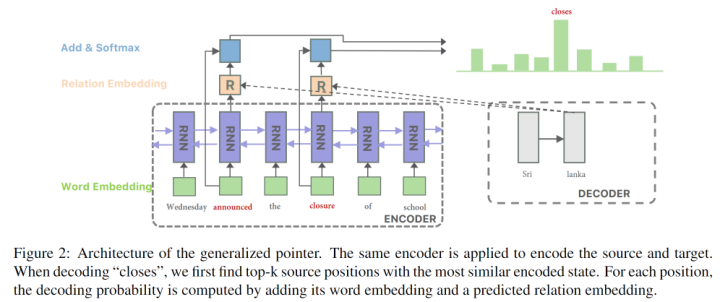
本文提出了一种模型,使得指针网络能够“编辑”其复制的词语,而不是简单地硬拷贝,来尝试解决上述问题。下图给出了一个启发性的例子,可以看到,黄金摘要中的每个词语都能近似地找出原文(Source)中的意思相近的词语(标红的词语),但是并不是完全复制,而是有一些略微的修改,例如:closure -> closes、campaign -> war、escalated -> escalates。

在标准的指针生成网络中,这些改变了词性的衍生词或近义词不会被包含在复制模式中进行训练,但它们确实与原文中的某个词具有词义上的相关性(即软对齐),作者认为这限制了摘要的生成效果,尤其是在摘要概括度很高的数据集中。
本文提出了泛指针生成网络(Generalized Pointer Generator,GPG),将指针生成部分的“硬拷贝”替换为“软编辑”。如上图,模型在生成closes的时候,先指向原文中的closure一词,然后通过一个关系建模函数将closure转换为closes进行生成。
Model
记号
输入序列:
输出序列:
第 时间步,编码器编码后的隐层状态:
第 时间步,解码器解码时的隐层状态:
对 做注意力后的注意力权重: ,其中 为计算向量相似度的函数。
对 做注意力后的加权和:
Seq2Seq with Attention
在每一个解码时间步 ,将 与 拼接后,映射到中间向量,随后映射到词表维度,然后经过softmax得到预测概率:
Pointer Generator
在每一个解码时间步 ,首先算一个生成概率:
随后词表中每个词的生成概率为“生成模式”的对应概率和“指针模式”的对应概率分别按 和 加权求和的结果:
Generalized Pointer Generator (GPG)
在 式中, 当且仅当 和 完全相同时为1,作者认为这限制了“指针模式”的表达能力,作者通过修改 这一项来扩展指针生成网络:
首先获取指针指向位置的词向量 ,然后通过一个关于 和 的函数 对该词向量进行“编辑”,随后类似 式,将编辑后的向量映射为词表维度,经过softmax得到生成概率。这里的 可以是任意函数,在实验中作者采用的是多层前馈网络。
这里背后的思想很直接:人类常常先通过选取原文中的某个词,然后考虑在当前语境中需要使用何种关系(时态转换、近义词/同义词、上位词、下位词等),最后将原文的词语 转换为所需的目标词语 ,举例:boy -> child(概括)、liked -> like(时态转换)、person -> man(精确描述)等。
Estimate Marginal Likelihood
从 式到 式,相当于每一个生成时间步 ,都需要对原文中的每一个词 进行一个预测(softmax),因此训练时的复杂度变成了原来的 倍( 为输入文本的长度)。为了使训练代价可接受,作者采用了top-k近似的方法,即:在每个解码时间步,选取概率最高的k个位置。
作者采用的评估方法如下:用一个上下文编码器(例如ELMo)对输入文本和黄金摘要进行编码,然后从原文中选取和目标词编码向量距离最近的k个位置,距离度量采用向量内积。最终的目标函数如下:
注意这一步只在训练时进行,因此就能够获取到输出的上下文编码。
Experiment
作者在三个摘要数据集CNN/DM(online news summaries)、English Gigaword(paired the first sentence of news articles with its headline)、XSum(one-sentence summary for BBC long story)上进行了实验。
对所有模型都使用了单层bi-LSTM作为编码器,隐层大小相同,词表为30k,输入和输出的word embedding共享。
比较模型:
- Seq2seq:即Seq2Seq with Attention
- Point.Gen.:即Pointer Generator,指针生成网络
- GPG:本文提出的模型
- GPG-ptr:只包含拷贝模式的GPG,用来比较
实验结果
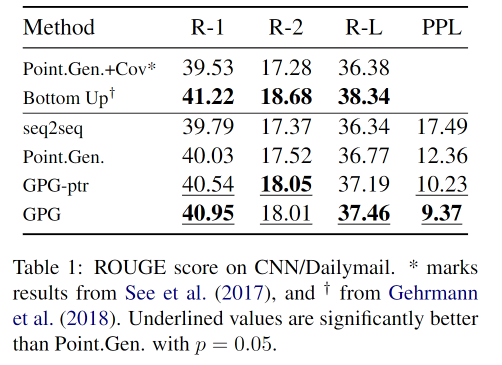
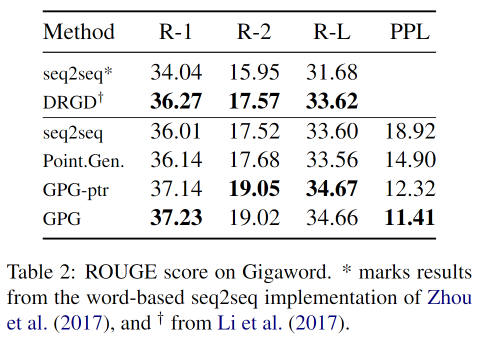
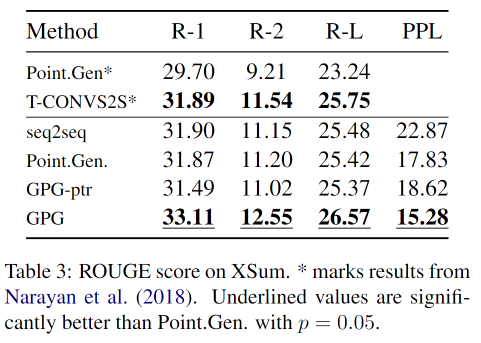
不同k值的影响
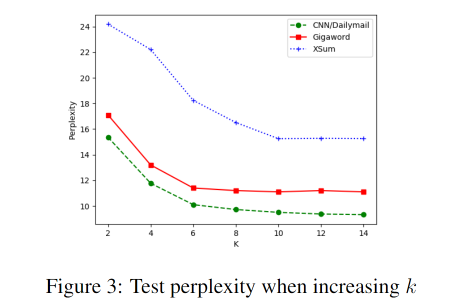
可以看到随k值增大,在测试集上的困惑度降低。
抽象程度
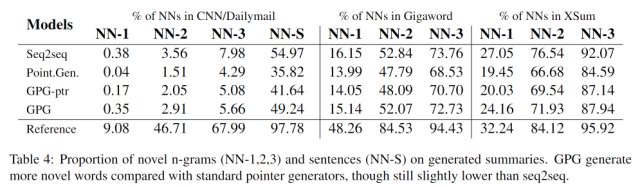
这里NN-n是生成的摘要中,未在原文出现过的n-gram的比例。可以看到其中Seq2seq > GPG > GPG-ptr > Point.Gen.。尽管Seq2seq最高,但其生成的很大一部分都是幻想出来的事实。
拷贝和生成的比率
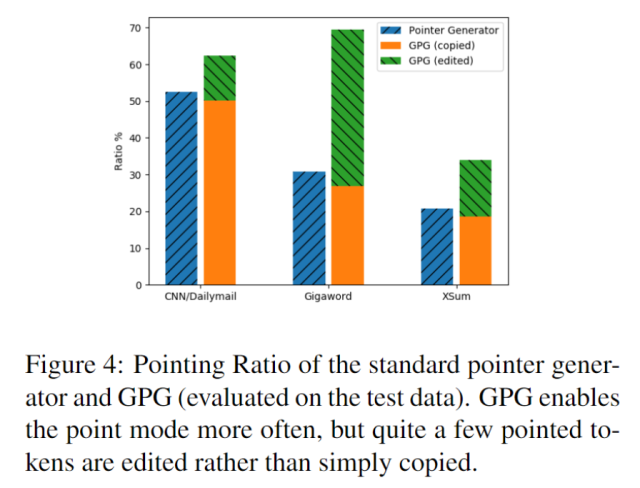
上图给出了不同数据集中拷贝生成的比例。其中左边一列是使用正常的指针生成网络统计的比例;右边一列是使用本文提出的GPG生成的比例。可以看出GPG相比传统硬拷贝的指针生成网络,能够捕获大量的隐式对齐,尤其是在Gigaword(中)这一数据集中。
Conclusion
本文提出了泛化指针网络(GPG),使得拷贝模式能够编辑原文词语而不是单纯硬拷贝。实验显示本文提出的模型能生成更抽象的摘要,同时相比于硬拷贝,能够捕获更加丰富的潜在的对齐效果,有助于模型的可控制性和可解释性。未来的工作包括:引入现成的外部知识来帮助更好地建模转换关系,以帮助低资源条件下的训练。